Hi everyone,
As I’ve mentioned in other threads, we (ftrack) are working a brand new publish UI for our integrations, and we’re experimenting on using Pyblish for this.
I’ve been asking questions about pyblish both on the forum ( Filtering collected instances based on category/family
and Selecting instances
) as well as sharing some information privately.
First of all some background on our goals:
- Provide a consistent publish experience across applications and departments (as far as possible). We think that pyblish can be an important part of this.
- Make an approachable UI that is easy for the artist to understand and use. This means that we don’t want to overwhelm them with options and information that is not relevant.
- Should work out-of-the-box and not requiring any technical expertise to setup. So very low configuration requirements to get started. This has some implications on what we can and cannot do. E.g. we cannot guarantee that there will be a certain task type, or asset type in ftrack - and as far as possible we would like to be agnostic to this.
- Under the hood it must be powerful and extensible for our fellow developers. Studios works differently and we must allow a lot of customisation. This is also where we hope pyblish plugin capabilities will shine

With these goals in mind I’ve written a prototype / technical preview of how our publish tools could work. It does not reflect final thoughts and design, but should hint on what we’re considering workflow-wise. Here is a video of the interface: video for download
And here is a screenshot:
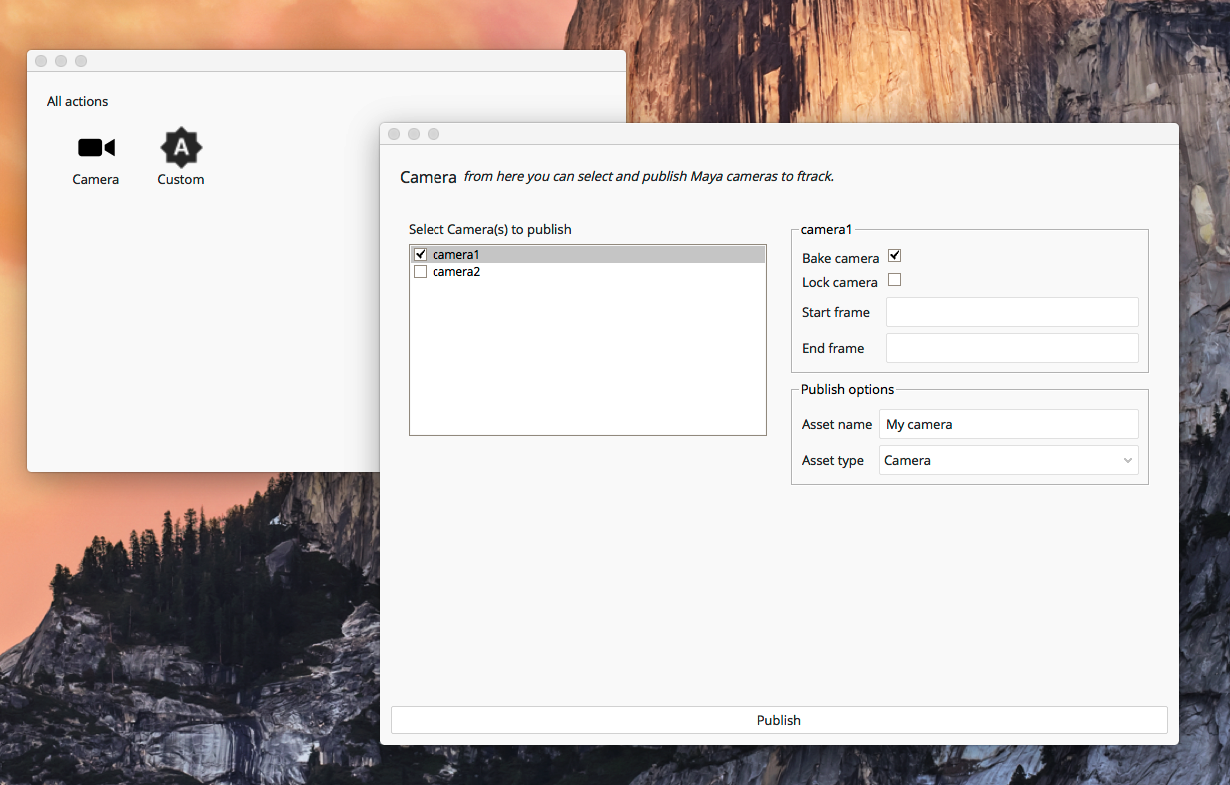
A few things I would like to point out in this video:
A) The initial dialog let’s the user decide what they would like to publish. In the video there are two options: Camera and Custom. The registration of these works like a traditional (synchronous) ftrack Action and when launched the UI is opened as:
dialog = ftrack_pyblish_maya_prototype.pyblish_ui.PublishDialog(
label='Camera',
description=(
'from here you can select and publish Maya cameras to ftrack.'
),
instance_filter=(
lambda instance: instance.data.get('family') in ('camera',)
)
)
As you can see the dialog is opened with a filter that only let’s the user pick from a defined set of instances. The Custom action will not filter instances at all, so artists can pick any combination they want.
B) The publish dialog will show you all valid instances for your selected publish action. Instances will be grouped on family.
When selecting an instance we set a publish boolean in the instance.data. From
Filtering collected instances based on category/family I understand that this is debated and that it is recommended to persist this into the scene. It is still something we’re discussing and maybe something that can be left to the Studio to decide (see #4 in the goals).
C) When an instance is selected we’re also displaying a set of options for the instance. In the current implementation the options are provided by the instance plugins with a matching family above Collector order.
The options that I’ve implemented are based on the ftrack action UI specification: http://ftrack.rtd.ftrack.com/en/stable/developing/actions.html. I’m aware that these are probably too basic and that many situations will require a lot more control. This is something we’re still researching, but I want to get this out here so that we can discuss the overall approach.
Again, I assume this to be a rather hot topic. Based on the discussions of selecting instances I guess that many of you will want this information to be persisted into the scene so that subsequent publishes will work the same. And also if you would do the publish on another machine the same scene + pyblish plugins would produce the same result. I’m not sure what path we will take here but I’m interested in your thoughts.
Here is some code that I’ve been experimenting with - not in any way a final design but you can see my intentions:
class ExtractMayaCamera(pyblish.api.InstancePlugin):
'''Extract maya cameras from scene.'''
order = pyblish.api.ExtractorOrder
families = ['camera']
def process(self, instance):
'''Process *instance* and extract maya camera.'''
if instance.data.get('publish'):
print (
'Extracting camera using options:',
instance.data.get('options')
)
ExtractMayaCamera.__ftrack_options = [{
'type': 'boolean',
'label': 'Bake camera',
'name': 'bake_camera'
}, {
'type': 'boolean',
'label': 'Lock camera',
'name': 'lock_camera'
}, {
'type': 'number',
'label': 'Start frame',
'name': 'start_frame_camera'
}, {
'type': 'number',
'label': 'End frame',
'name': 'end_frame_camera'
}]
When an option is modified it is saved in dictionary instance.data[‘options’] so that it is available when processing.
D) On the bottom right corner there is a "Publish options” section. These are options gathered from plugins above Collector order that runs on the Context. It works the same way as for instance plugins but when an option is modified it is saved in dictionary context.data[‘options’] so that it is available when processing.
~
I’ve added a bitbucket repo with the prototype code. I want to point out that this is a prototype that focuses on how our pyblished based publish tool could work. So try not to judge me on code quality or architecture 
Anyhow, here is the repository if you want to browse the code: https://bitbucket.org/ftrack/ftrack-pyblish-prototype/overview. It is not a public repo so ping me here or privately with your bitbucket account name and I will let you in.
Do I have to say that I’m awaiting your feedback?