Magenta Contract
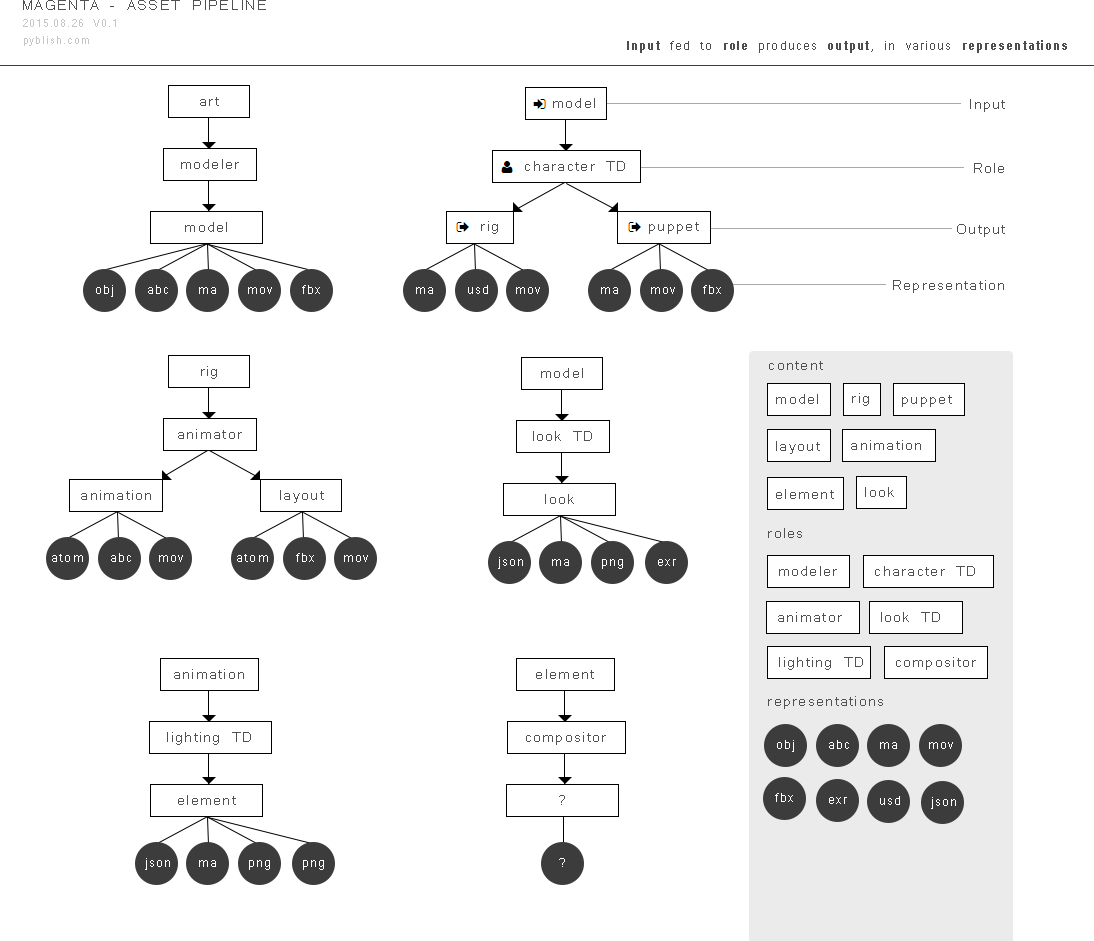
Here is a summary of how the different families in Magenta are currently identified and collected. Call it “the contract”
Table of families
- metadata
- model
- rig
- pointcache
- animation
- layout
- lookdev
- renderlayer
Each family is given a series of attributes so we can more easily compare and contrast them against each other.
tasks: Which task typically produce instances of this family
hosts: Hosts used for this task
identifier: How collection separate this instance from everything else
inputs: Optional inputs to the task, such as a model for rigging
outputs: Type of information leaving a host, such as a mesh
representations: File formats of outputted files
destination: Absolute path of output after integration
file: Fully qualified filename of output after integration
I’ll update this post as we go.
Changelog
-
2015-08-19 15:00 - Added sections metadata and layout.
-
2015-08-20 13:85 - Added table of families
metadata
Generic task and content information.
tasks: ["any"]
hosts: ["any"]
identifier: -
inputs: []
outputs: ["data"]
representations: [".json"]
destination: "{project}/assets/{asset}/{task}/public/{version}/{instance}/{file}"
file: "{project}_{sequence}_{shot}_{version}_{instance}.{repr}"
workflow
For every published asset, metadata is published regarding context-sensitive information relevant to other pipeline steps.
- Author
- Date
- Project
- Item
- Task
- Contained Assets
Most importantly, this information can be used to track assets used in other assets. Such as, figuring out from where a model was originally imported in a rig, or which rig was used in a pointcache.
This information is used to associate a pointcache with shaders from its associated lookdev.
model
The geometry of an asset
tasks: ["modeling"]
hosts: ["maya"]
identifier:
- assembly with ITEM name and "_GRP" suffix, e.g. "ben_GRP" +
- environment variable TASK == "modeling"
inputs: []
outputs: ["mesh"]
representations: [".ma"]
destination: "{project}/assets/{asset}/{task}/public/{version}/{instance}/{file}"
file: "{project}_{sequence}_{shot}_{version}_{instance}.{repr}"
workflow
Artists model in Maya using only polygons. Any other node, such as NURBS, history of any kind and keyframes are allowed, but are not included on publish.
room for improvement
The two-factor identifiers. Ideally I’d like a model to appear as a model, regardless of its environment. The assembly could, for example, have a user-defined attribute on it saying “I’m a model”. Or an assembly with a uniquely identifying suffix, such as _MODEL or even prefix such as model_GRP.
To not burden the artist, an initialisation step could be added in place of starting fresh. For example, a “Create Asset” dialog with drop-down indicating what sort of asset is to be created. The procedure could then automatically apply the appropriate user-defined attribute along with setting up the appropriate assembly into which the model is to be created.
rig
The encapsulation of content into an interface in preparation for use/animation by other artists.
tasks: ["rigging"]
hosts: ["maya"]
identifier:
- assembly with ITEM name and "_GRP" suffix, e.g. "ben_GRP" +
- environment variable TASK == "rigging"
inputs: ["model"]
outputs: ["any"]
representations: [".ma"]
destination: "{project}/assets/{asset}/{task}/public/{version}/{instance}/{file}"
file: "{project}_{sequence}_{shot}_{version}_{instance}.{repr}"
workflow
Namespaced as {instance}_. E.g. ben_. {instance} is important to distinguish it from other referenced assets whereas the underscore is pure-cosmetics and makes namespaces appear as a regular separator. ben_:ben_GRP versus ben:ben_GRP.
Once referenced, the rig is stored in an assembly much like it’s model equivalent. The internal structure is as follows.
▾ ben
▾ implementation
▸ inputs
▸ ...
▸ outputs
▾ interface
▸ controls
▸ preview
▸ controls
▸ pointcache
in-depth
# The assembly, suffixed _GRP for collection
▾ ben
# The bulk of a rig, including, but not limited to, deformers,
# auxiliary geometry, dynamics and constraints
▾ implementation
# The source geometry in it's undeformed state
▸ inputs
# The various operations to be performed on a rig
# in top-down order. I.e. the top-most operation
# happens before the next. Similar to the channel-box.
▸ ...
# The resulting geometry/nodes from the above operations
▸ outputs
# The implementation is always hidden from view.
# The interface is what an artist interacts with
# and sees.
▾ interface
# Standard NURBS controllers, driving the above
▸ controls
# Visible, non-editable DAG nodes, including meshes and helpers
▸ preview
# An objectSet containing all animatable controllers
▸ controls
# An objectSet containing all cachable geometry
▸ pointcache
References are baked into the file upon publish; i.e. no nested references.
room for improvement
- The duplicate information in the full name,
ben_:ben_GRP, it doesn’t reflect from which task or family the content is from. It could say e.g. ben_:model_GRP
- To prevent artists from re-creating this hierarchy, or creating it wrongly, an initialisation phase could be added; similar to with the above suggestion for Modeling. Essentially the same dialog box, selecting “Rig” and it would assign the proper user-defined attribute and create the hierarchy fixture.
lookdev
The look of an asset.
tasks: ["lookdev"]
hosts: ["maya"]
inputs: ["model"]
identifier:
- Object set called exactly "shaded_SET"
outputs: ["shader", "link"]
representations: [".ma", ".json"]
destination: "{project}/assets/{asset}/{task}/public/{version}/{instance}/{file}"
file: "{project}_{sequence}_{shot}_{version}_{instance}.{repr}"
workflow
An artist references the model of an asset and assigns shaders to it, along with user-defined attributes onto the meshes themselves. Shaded meshes are added into an object set called exactly shaded_SET.
contribution
Meshes in shaded_SET are examined for their associated shaders. These shaders are exported, along with their shading groups and graph; such as textures and light links.
As the outputted Maya scene file does not include the meshes themselves, we need a third-party to link a mesh with it’s relevant shader. This is where .json comes in.
Each shaded mesh and component is serialised to JSON and linked with the corresponding mesh via a unique identifier. The mesh and shader can then later be re-assembled during e.g. lighting.
room for improvement
As opposed to previous steps, the identity of shaders and it’s correlation to meshes is independent of the environment. Once a set called shaded_SET is found, it’s meshes are probed for shaders and all of the above happens automatically.
I’m considering whether it could be a good idea to discard the suffix _SET as it is such a key node. In fact in general, I’m thinking key nodes are to be without suffix, to highlight their importance and singularity.
layout
Assets associated and positioned within a shot, with optional animation.
tasks: ["layout", "animation"]
hosts: ["maya"]
inputs: ["rig"]
identifier: ?
outputs: ["inventory", "transforms", "animation"]
representations: [".json", ".atom"]
destination: "{project}/film/{sequence}/{shot}/public/{version}/{instance}/{file}"
file: "{project}_{sequence}_{shot}_{version}_{instance}.{repr}"
workflow
contribution
Layout generates a plain list of assets associated with a shot - a.k.a. inventory. For example.
ben01
ben02
table01
sofa01
sofa02
The inventory may then be used to populate the shot for final animation.
In addition to a shotlist, a static position of each relevant asset is produced, such that it may be positioned according to the layout artists design, who may in turn have followed a guide such as a storyboard or animatic.
Optionally, and additional animation may also be produced from Layout which may then be applied during final animation as a starting point for animators. The animation is stored as .atom.
pointcache
Animation serialised into point-positions and stored as Alembic.
tasks: ["animation"]
hosts: ["maya"]
inputs: ["rig"]
identifier:
- Object set called exactly "pointcache_SET"
outputs: ["mesh"]
representations: [".abc"]
destination: "{project}/film/{sequence}/{shot}/public/{version}/{instance}/{file}"
file: "{project}_{sequence}_{shot}_{version}_{instance}.{repr}"
workflow
Artists reference rig instances and apply keyframe animation. Each rig is referenced under a pre-determined namespace.
Namespaced as {instance}{occurence}_. E.g. ben01_. {instance} is important to distinguish it from other referenced assets, and {occurrence} allows to reference the same asset multiple times. The underscore is pure-cosmetics and makes namespaces appear as a regular separator. ben01_:ben_GRP versus ben01:ben_GRP.
contribution
Only meshes and point-positions are present, along with the .uuid of each shape node. This means no transform values or animation curves.
animation
Animation serialised into curves and store as Atom.
tasks: ["animation"]
hosts: ["maya"]
inputs: ["rig"]
identifier:
- Object set called exactly "pointcache_SET"
outputs: ["curves"]
representations: [".atom"]
destination: "{project}/film/{sequence}/{shot}/public/{version}/{instance}/{file}"
file: "{project}_{sequence}_{shot}_{version}_{instance}.{repr}"
It hasn’t been implemented yet.
workflow
Like with pointcaches, a rig is referenced and animated and the same rules apply, only in this case the animation can be applied afterwards to the original rig; no point-positions are involved.
contribution
Only transforms are considered, those present in the controls_SET.
render
Combined pointcache and lookdev into a rendered sequence of lit images.
tasks: ["lighting"]
hosts: ["maya"]
inputs: ["rig"]
identifier: ...
outputs: ["images", "quicktime"]
representations: [".png", ".mov"]
destination: "{project}/film/{sequence}/{shot}/public/{version}/{instance}/{file}"
file: "{project}_{sequence}_{shot}_{version}_{instance}.{repr}"
workflow
An artist references the relevant pointcaches produced by animation and applies shaders from lookdev. Shaders are deduced and applied automatically from the given pointcaches. That is, a pointcache of ben for shot 1000 are given shaders from the lookdev of ben the asset.
Rendering occur without the influence of publishing, as plain files on disk. The artist then publishes the resulting files directly off disk.
contribution
For The Deal, output is plain png, though any format should do.
room for improvement
-
@tokejepsen mentioned that sometimes, job submissions to a farm may need to be validated. See how this could fit into this methodology.
Notes
I’ll keep this post updated with changes as we go. Ultimately, this should represent each and every detail of how each individual family is first identified and finally outputted, minus validation.
Feel free to comment on things, we’ll rely on the version control of this post to track what each reply was in regards to (by looking at the date of the reply, and scanning edits of the post).
 Or is that part of animation as opposed to pointcache?
Or is that part of animation as opposed to pointcache?