Totally correct. My formatting was based on the assumption that the published paths would be Family-first and as such identify that the contents in there all hold a “model” only of different instances.
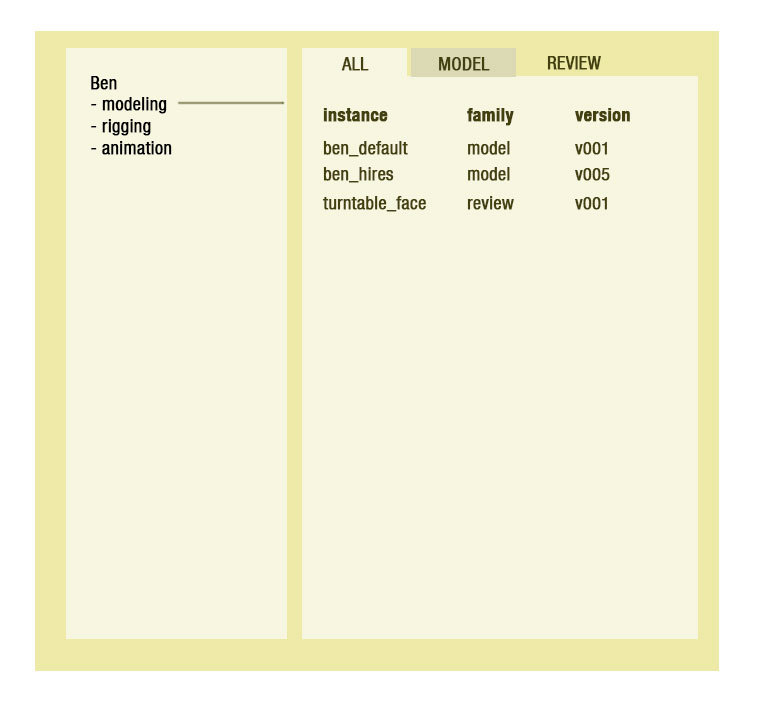
item: The name of the item you’re working on. It’s the name of the asset or shot. For example our character “ben” or the shot “1000”.
task: A single step/stage in the production of the item. For example “modeling” or “rigging”.
Note: Since any Task can output any type of data it’s all up to the “workflow” of the project to make assumptions about what data is created where. For example it’s recommended (since it makes sense) that a “modeling” task is done to create the final model for a character.
family: The type of output data coming from the artist working in the task. These can range from model, rig, lookdev to pointcache or even review. This is the family used to define the content within the Pyblish plug-ins.
instance: The instance of output data the artist is generating, in most scenarios there would be a “default” expected output so we recommend outputting as such: ben_default. Other instances then could be: ben_hires or ben_proxy. Similarly the separate pointcaches from an animation scene would all be there own instance (within the family of pointcache).
version: This would the be automatically incrementing version number of the output data. Each family/instance combination would have its own versioning since it is its own version of the output data that it represents.
Note: Since versioning is based on each family/instance combination model/ben_default and review/ben_default would increment separately. Similarly when performing a “similar” extraction in another task, for example outputting a model in rigging would also be its own output folder. This should all be clear from looking at the folder structure and how things are grouped.
Example
So we’ve defined the following pattern: {item}/{task}/publish/{family}/{instance}/{version}/...
You’re rigging the character Ben and want to output its main (= default) rig, this would be:
item = "ben"
task = "rigging"
family = "rig"
instance = "ben_default"
version = 1 # formatted to "v001"
It seems to me that you have arrived to something I’ve touched upon in this thread
considering you can publish any content from any task, wouldn’t it make more sense to be publishing into a shot/asset publish folder, rather than task publish folder?
let’s say that someone working on lighting task creates a new model, it get’s placed into lighting publish folder. Quite frankly I can’t imagine anyone looking there for the data. However publishing it to a shot publish folder is clear, because everyone knows to go there if they need something, regardless what task it came from.
your example would then be: {item}/{task}/publish/{family}/{instance}/{version}/...
hence ben/publish/rig/ben_default/v001/...
no duplication of data (rigging task and rig family), and all publishes in one structured folder. Easy for tools and people to understand.
I think your conflict has just grown. Because then it’s not immediate apparent that a model might have been published from a rigging task (which shouldn’t be the “final model”)? Or should it?
Also publishing a camera from both the animation department and the layout department as the exact same output data is just as problematic on its own? Reading that topic it seems you can’t easily identify who worked on it last? Do they often work in parallel? If so they would “compete” with their versions, both incrementing one after the other. This would make it just as hard to find the correct camera? I think this is more of a “social” problem?
If there’s a need to trace (view) “versions” between multiple departments/tasks and want to see who pushed the latest update than it would be up to browser that filters it as such. For example you could make a ListView that shows published contents “by family” like how some e-mail inboxes can merge multiple inboxes. There’s still enough reason to have the content itself be separate.
Anyway, I have thought about this as well. Seeing that you’re bringing this up I need to think about it some more.
That is true if rigger was publishing the same instance as modeller. I would hope however, that modeller would publish ben_default and ben_hires, but rigger would create a new instance for his models: ben_proxy, ben_blendshapes.
In case of camera We’d be separating them too. cam_track, cam_lay, cam_anim.
Directly from the file you couldn’t but, that is the same for task based publishes if you have multiple people working on the same task. We use database (ftrack) to keep track of who published what.
Not really. Never in parallel on the same task if there is a big set to build, it would be split to model_props, model_structures tasks. or similar. In case we have more people on the same task they would never work on it on the same time. That doesn’t make much sense to me.
Absolutely more of a ‘social’ problem. In terms of finding the latest version of a camera there isn’t any difference I think. If I’m compositor who wants to import camera to 3d comp it makes no difference whether I first go to previous task and pick a camera, or go to cameras and pick the one exported from the task I want (most likely lighting.)
just as a side note. I’m really not trying to push towards dropping the tasks from publishing. It just appeared to me that that’s where you were headed.
Thanks for explaining. I think in the end a browser that gives you the opportunity to “list by family” from all Tasks is more what you’re looking for, especially since you’re still recommending to separate the camera into their own “instances” anyway.
Once we get an asset browser going with Magenta along with the corresponding API I hope to show you a way you’ll grow to love.
yeah, say you have a character lookdev that is using renderlayers to get out two different renders.
Are you referring to a shader variation?
Like an object being either Blue or Red?
We’re supporting that.
If you mean you want to preserve renderLayers (like you have a complex layer than can’t operate as a pass) we’re currently not handling this. Yet we definitely could!
We have enough information about our nodes to identify every single one and export and recreate layers with overrides in the render scene. The tricky thing here is what happens if you have the same object multiple times.
What’s the expected use case?
Do they get combined in the same renderLayer?
Or what happens if you have a similar layer among multiple objects? eg. Two assets both having a same named “special” layer.
You setup your renderlayers once, in the lookdev file, and that progresses down the pipe to the shots.
Good questions:) Haven’t encountered using multiple assets of the same kind that uses renderlayers. In theory, I guess I would expect to not combine them, and get out masks for comp for merging them together. With rebuilding the layers, this is definitely an added bonus, that you would be able to choose to combine layers or not.
Of course a choice could be provided. Do you have an example use case of what kind of “layers” are usually set up per object as opposed to being scene-wide in a lighting scene?
If you have a very specific example we can keep it into account.
Have some use cases, but it mostly very generic that we often use renderlayers per object. Right now we are using renderlayers to get out some paint effects with maya software along with some shaders from mental ray, so the renderlayer helps us switch renderer.
I wouldn’t worry too much, I was mostly asking whether you guys had a solution in place that I could look at.
Yeah, looks good. Probably something for the future.