This way representations are evenly represented with a dotted suffix - e.g. .exr - even though some of the childen of a version are directories instead of files.
Where high_res is a new identifier that we haven’t used with assets before, but is needed so we can use the identifier for each pass during rendering. When an asset doesn’t have this identifier (should we call it output, as in the name of an “output” from a family?) then it’s given default.
Passes are then output from a pipeline perspective, and it’s full name is prefix + output + representation.
Had a chat with @marcus on hangouts and here’s some of the next steps we want to take with Magenta; I’ll separate them into their own posts.
Any Task can create any type of output/representation.
Currently
Currently collecting what is important for extraction for a model is based on what item we’re working on and where we’re working on it. In short we can only export a model from modeling. We’ve come to an agreement that this is particularly bad.
Goal
We feel that an Artist should be allowed to choose and be “explicit” what contents can and should go out from his scene. This also allows arbitrary data to be extracted from a scene if a particular workaround requires it. Plus it forces the artist to think more (and also easier limit) what’s required for export.
Proposition
An Artist would put the contents into an objectSet or another entry that is tagged as such within the scene’s content.
Plus a single node can be present in multiple sets.
Say a camera might be used for “review” in an objectSet to perform a capture of the scene plus it should be published as a camera along with the animation scene. This way then can be managed independently.
@mkolar, @tokejepsen and @tomhankins. You seem to have more general expertise in ‘lighting/compositing’ area. Hope you all can contribute here.
This sounds really really good, though I think a model in different resolutions is exactly one of those things that you’d want to increment in version separately? We rarely have a high-res/low-res separation of assets going on, except for proxies. These proxies are generally created separately.
What I’m most afraid of is that we end with an assumption of ‘default’ and ‘high-res’ always being present. Could an early version get published without the high-res present? What happens when the high-res is created a week later? Does that merge into the currently available version number?
Totally correct. My formatting was based on the assumption that the published paths would be Family-first and as such identify that the contents in there all hold a “model” only of different instances.
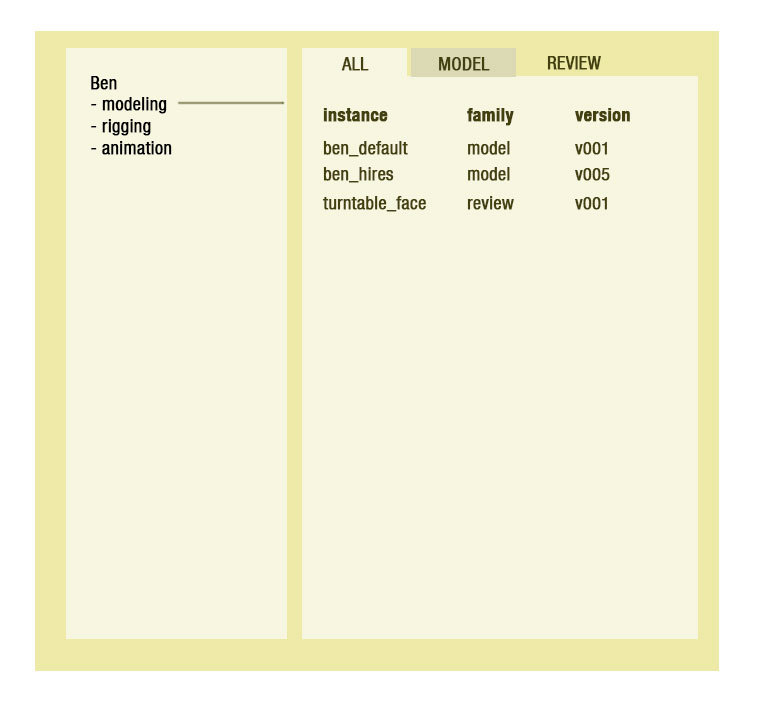
item: The name of the item you’re working on. It’s the name of the asset or shot. For example our character “ben” or the shot “1000”.
task: A single step/stage in the production of the item. For example “modeling” or “rigging”.
Note: Since any Task can output any type of data it’s all up to the “workflow” of the project to make assumptions about what data is created where. For example it’s recommended (since it makes sense) that a “modeling” task is done to create the final model for a character.
family: The type of output data coming from the artist working in the task. These can range from model, rig, lookdev to pointcache or even review. This is the family used to define the content within the Pyblish plug-ins.
instance: The instance of output data the artist is generating, in most scenarios there would be a “default” expected output so we recommend outputting as such: ben_default. Other instances then could be: ben_hires or ben_proxy. Similarly the separate pointcaches from an animation scene would all be there own instance (within the family of pointcache).
version: This would the be automatically incrementing version number of the output data. Each family/instance combination would have its own versioning since it is its own version of the output data that it represents.
Note: Since versioning is based on each family/instance combination model/ben_default and review/ben_default would increment separately. Similarly when performing a “similar” extraction in another task, for example outputting a model in rigging would also be its own output folder. This should all be clear from looking at the folder structure and how things are grouped.
Example
So we’ve defined the following pattern: {item}/{task}/publish/{family}/{instance}/{version}/...
You’re rigging the character Ben and want to output its main (= default) rig, this would be:
item = "ben"
task = "rigging"
family = "rig"
instance = "ben_default"
version = 1 # formatted to "v001"
It seems to me that you have arrived to something I’ve touched upon in this thread
considering you can publish any content from any task, wouldn’t it make more sense to be publishing into a shot/asset publish folder, rather than task publish folder?
let’s say that someone working on lighting task creates a new model, it get’s placed into lighting publish folder. Quite frankly I can’t imagine anyone looking there for the data. However publishing it to a shot publish folder is clear, because everyone knows to go there if they need something, regardless what task it came from.
your example would then be: {item}/{task}/publish/{family}/{instance}/{version}/...
hence ben/publish/rig/ben_default/v001/...
no duplication of data (rigging task and rig family), and all publishes in one structured folder. Easy for tools and people to understand.
I think your conflict has just grown. Because then it’s not immediate apparent that a model might have been published from a rigging task (which shouldn’t be the “final model”)? Or should it?
Also publishing a camera from both the animation department and the layout department as the exact same output data is just as problematic on its own? Reading that topic it seems you can’t easily identify who worked on it last? Do they often work in parallel? If so they would “compete” with their versions, both incrementing one after the other. This would make it just as hard to find the correct camera? I think this is more of a “social” problem?
If there’s a need to trace (view) “versions” between multiple departments/tasks and want to see who pushed the latest update than it would be up to browser that filters it as such. For example you could make a ListView that shows published contents “by family” like how some e-mail inboxes can merge multiple inboxes. There’s still enough reason to have the content itself be separate.
Anyway, I have thought about this as well. Seeing that you’re bringing this up I need to think about it some more.
That is true if rigger was publishing the same instance as modeller. I would hope however, that modeller would publish ben_default and ben_hires, but rigger would create a new instance for his models: ben_proxy, ben_blendshapes.
In case of camera We’d be separating them too. cam_track, cam_lay, cam_anim.
Directly from the file you couldn’t but, that is the same for task based publishes if you have multiple people working on the same task. We use database (ftrack) to keep track of who published what.
Not really. Never in parallel on the same task if there is a big set to build, it would be split to model_props, model_structures tasks. or similar. In case we have more people on the same task they would never work on it on the same time. That doesn’t make much sense to me.
Absolutely more of a ‘social’ problem. In terms of finding the latest version of a camera there isn’t any difference I think. If I’m compositor who wants to import camera to 3d comp it makes no difference whether I first go to previous task and pick a camera, or go to cameras and pick the one exported from the task I want (most likely lighting.)
just as a side note. I’m really not trying to push towards dropping the tasks from publishing. It just appeared to me that that’s where you were headed.
Thanks for explaining. I think in the end a browser that gives you the opportunity to “list by family” from all Tasks is more what you’re looking for, especially since you’re still recommending to separate the camera into their own “instances” anyway.
Once we get an asset browser going with Magenta along with the corresponding API I hope to show you a way you’ll grow to love.
 Shouldn’t we all just stick to Microsoft MovieMaker?
Shouldn’t we all just stick to Microsoft MovieMaker?