To be honest I think the Actions wouldn’t even need access to process_context() or process_instance() but more so to something like process_plugin() and (whenever it requires context it takes it from the plug-in?). This also makes it less likely for people to use it as something that adjusts the context/instance?
They might not need to, but there might be cases in which it would make sense.
For example, if a validation fails and you were interested in writing an Action to select the failing portions of the scene, the Context and Instance could contain knowledge about what to select.
class SelectPerpetrators(pyblish.Action):
def process_instance(self, instance):
cmds.select(instance)
The same goes for repairs.
class SolvePerpetrators(pyblish.Action):
def process_instance(self, instance):
cmds.delete(instance.data("badNodes"))
New users can get away with neither.
class SolvePerpetrators(pyblish.Action):
def process_context(self, context):
cmds.delete("myNode_GEO")
Though ideally the method they override wouldn’t contain information that is not relevant to them, such as when dependency injection is active.
class SolvePerpetrators(pyblish.Action):
def process(self):
cmds.delete("myNode_GEO")
All clean.
Specificity
It may also make sense to be specific with your action, such as applying it only to a particular Plugin/Instance combination. In this case, the instance chose would be passed to process() via it’s instance argument.
I still have to adopt the mindset that all data ever being used will be going into the Context or Instance instead of getting it from the Plug-in itself. For me it’s still that the data of invalidated nodes is so linked to the Validator that I would assume the data gets stored on the Validator, but I can see how that would make it much harder to use the data outside of the plug-in. Especially with storing all invalidated nodes’ data into a database or log at the end it’s easier if the data is inside the context/instance (as it should be).
Maybe it would make it easier think of plug-ins more like nodes; each node is stateless and just takes data in, does something to it, and then pushes it back out.
Actually that is the wrong example. That makes me think the data is retrievable as an output on the node, not on the Context. I would say it’s more like a traffic highway going to one destination and each plug-in will end up at the same destination, which is the resulting Context?
But I get your point, you mean more as a Node that has incoming data and adds to that data as opposed to one that has incoming attributes and provides other/new output attributes (the latter is the terminology I’m used to from Maya).
Had some ideas that correlate to this topic, but haven’t been able to clearly define it yet, so I’m sharing it here for reference.
What’s wrong with Repair?
Besides the conceptual barrier of publishing versus repairing, which we have covered many(1) times(2) before(3), repairing is difficult from an implementation point-of-view primarily because of how it can affect either the Context, an Instance or many Instance's.
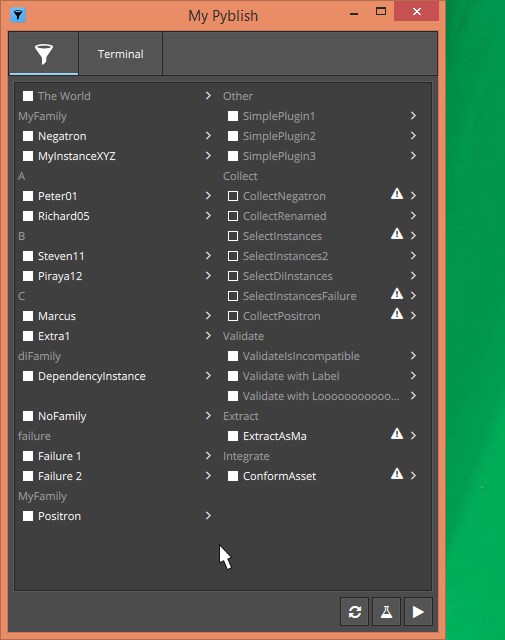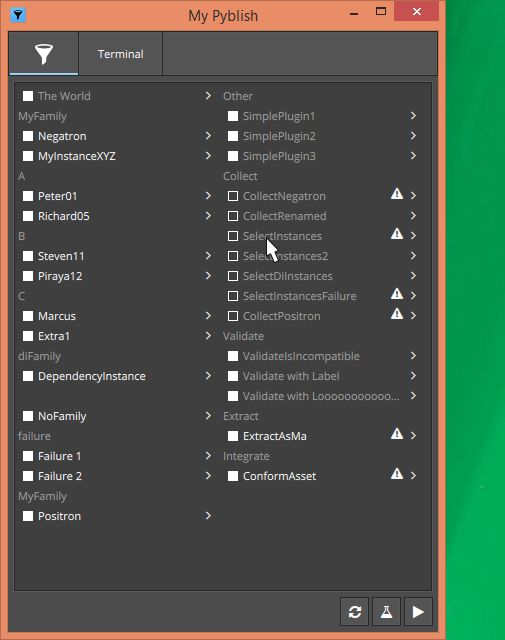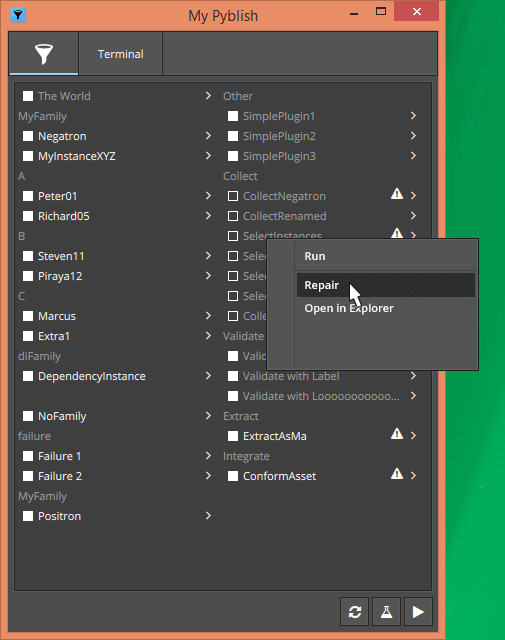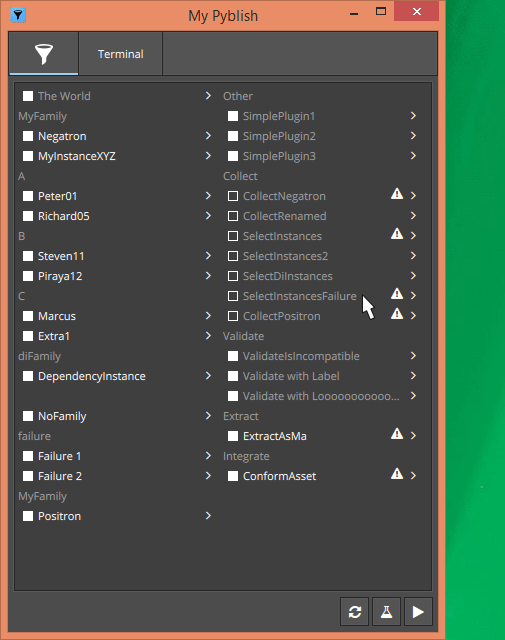
It is also difficult from a user-experience point-of-view. Currently, the repair-button in the GUI is located next to the plug-in such that it is clear what method is being run to actually perform the repair; but what isn’t clear is which instance it applies to, or if it involves the context.
Besides it’s usefulness, which has also been discussed in the above links, repairing is about solving problems and validations are in their very nature looking for such problems. Having the solution and problem coupled together in this way is highly intuitive. It means the solution to any given problem is provided to the user in context with the problem.
As in, the user is able to solve a problem, only when a problem is present to begin with.
What can we do?
Here’s an optional name for Action it that more clearly suggests that it only relates to solving problems and that it only appears when a problem has been found; Solution.
class SolveAge(pyblish.api.Solution):
def process(self, instance):
# solve problem
class ValidateAge(pyblish.api.Validator):
solutions = [SolveAge]
def process(self, instance):
# find problem
I think Solution could be a subclass for Action meant to be implemented for Validators to provide… well, a solution.
But I can also see benefits in being able to right-click the extractor after process and have custom Actions there, like “show output in explorer”. Possibly useful if an integrator failed. A similar action is just as useful for an Integrator to identify quickly where our files ended up.
Actions in general would be to allow streamlining our workflow with Pyblish by letting developers customize it for their own workflow/toolset without breaking the functionality of the UI (standalone or integrated) or even in batch mode. In short Actions would be about being able to extend Pyblish, whereas Solutions are a subset of that.
@marcus I was thinking about using Actions to add a Development category in the Context menu that would allow me to “Show Plug-in in Explorer”. From time to time I’ve had a hard time to figure out where a plug-in was exactly loaded from in the UI if multiple paths were involved. Do you think something like that makes sense?
And would it be easy to find the plug-in instance’s filepath from within the Action if the plug-ins were inherited from one top plug-in that had the action attached to it. (The Action is defined elsewhere)
Maybe something to have by default even? There’s been talk about making something like this available before, but nothing ever came up to provide the interface for it. This could be it.
It would be awesome if you could share what you come up with, and maybe even pull request to add a default.

 That makes me think the data is retrievable as an output on the node, not on the Context. I would say it’s more like a traffic highway going to one destination and each plug-in will end up at the same destination, which is the resulting Context?
That makes me think the data is retrievable as an output on the node, not on the Context. I would say it’s more like a traffic highway going to one destination and each plug-in will end up at the same destination, which is the resulting Context?