This is an opportunity for me to highlight in which direction I’m guiding you. When we’re done, I would like you to be able to say: “modellers, tag your work modelProxy, modelInternal or modelAnimation depending on your intent” where each family (read “contract”) is detailed on your wiki/forums.
modelProxy: "A low resolution, non-essential asset for optimal performance/memory"
modelInternal: "An asset only relevant to either you or those within your department."
modelAnimation: "Animation-friendly geometry, with uv's, no self-intersection and no manifolds"
At which point you, the developer, can design plug-ins that operate based on their intent. Internal assets for example may be allowed to skip some of the more thorough checks, whereas modelAnimation must pass the harshest of checks.
That’s a good way to frame the question. I would anticipate a lot of collectors, and then a lot of logic for assigning families.
Ok, this is good! Let’s try and tackle this.
There is a practice that I’ve more often come to recommend when it comes to making collectors, which is it to allow your td’s to make the decision about what family/families a particular asset belongs to. They know a lot more about the asset than any automated process ever will, and you can extract this information from them.
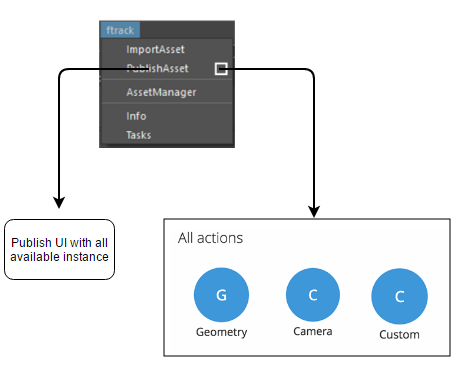
Have a look at this collector.
This one collector applies to every department, any family and moves the responsibility of you figuring out a family based on environment or circumstance to them assigning it themselves based on what they intend.
Part of the problem on my end is that we don’t have a very robust environment management setup, so there isn’t much data available in the environment for divining a user’s task.
Somewhat of a side track, but this is one of the reasons not just you may sometimes get an answer such as “No, Pyblish doesn’t do that”. I’ve made it my mission to ensure Pyblish only ever concerns itself with publishing tasks, so that remains lightweight and unbloated.
Before publishing, both of these questions need a “yes” answer.
- Is the data complete?
- Is it outgoing?
Yes, I tried phrasing it in that way to put it in context with Pyblish.
But the truth is, what is needed there falls outside the scope of Pyblish. As I mentioned above, the data must be complete. Your collector(s) depend on it.
Making data complete is opening a whole different can of worms, one that is equally deserving of one or more dedicated tools. I know @BigRoy is really busy at the moment, but he’s got the closest thing to what I try and steer developers towards. Maybe when he finds the time, he could share some of those.
Sorry, could you rephrase this? Just want to make sure I understand completely.
Thanks for excellent questions, this is great, and hope it helps!