At the original time of implementing that it wasn’t about families. On a more global level it was meant to store information like startFrame, endFrame, preRoll, etc. All the things you’d want to avoid “guesswork” to what the Artist intended. For us this made our scenes’ content much clearer. It actually becomes much easier for the artists in the long run: if they publish an update of a shot they don’t need to re-enter all this information, and of course ensure it’s consistent where it needs to be.
Whether it persists in the scene or in an asset management database of course would be all up to personal preferences. I’m purely debating the aspect of persisting those choices.
In a way you could see the “instance” that is created by user input and persists with it as a “mini-environment” in the scene. Basically that defines what gets run, whether that’s through some state managing of your environment or pyblish families I guess is up to you.
The problem is exactly in the end of that sentence. If you already know what you want to publish then there’s no need to push buttons or even have user intervention Once there’s two models coming from one scene, or a camera and a character coming from a scene (both separately) then it becomes a bit more guesswork to understand the Artists’ intentions. Does he even want to have that camera published? Similarly what frame to what frame are required for a pointcache? Does it need pre-roll? Handles?
Anyway, as we started taking more control of Publishing (moving to Pyblish made things easier for us, so we took it a step further) we learned more about possible pitfalls and also what were mindblowing improvements that we hadn’t expected. I’d say the best step at this stage is to leap in and run a production.
I absolutely agree that if you present all the instances to the user, it’ll quickly become overwhelming for them and they could potentially publish something they don’t intend on.
But I do think you can present the instances in GUI in a cleaner way, so they are more aware of what they are publishing. Currently the long list in pyblish-qml and pyblish-lite of instances, becomes unmanageble with 10+ instances to make a decision on.
If you had a section where the user could see all the instances, that are checked for publishing, which could be just two of 10+ instances, they would have a better overview of what they are publishing.
As a side note, we kinda had this problem with publishing from Hiero, where I present the user with all shots tagged for publishing. If the user had a video track with tens of shots, it would produce tens of instances, meaning it would become tedious to select specific shots to publish.
The solution was to collect the current selection when publishing (Hiero’s implementation is right-click menu), and only have those shots checked for publishing. This made it much quicker to publish specific shots, without having to reorganise the tags within the Hiero project.
In regards to filtering available instances prior to starting the ui (I can certainly see the usefulness of this in certain situations), it could also be sorted by having 2 publish options.
‘Full publish’ - Loads Pyblish GUI populated with all the available instances from the scene (the current default behaviour)
‘Selective Publish’ - Lets user pre-select the families he’d like to publish and then populates publishing GUI with only these. I’d go with something like checkboxes, so if user has a massive scene and only wants to publish camera and cache families, he can still do it in one go.
Technically this should be really easy to implement
This could simply be 2 separate publish buttons, with different behavior, or something like maya’s option box in the menus.
A whole other question is, whether just having a better, more organised GUI wouldn’t solve this issue in one big swipe. Ability to filter out families, collapse them and so on.
An option box is a good idea, both intuitive and non-obtrusive. Widening the GUI itself is also a good idea, I can see it go both ways.
To me, the GUI we have at the moment is quite minimal in contrast to how custom each publish could potentially become. I can see it grow into a much more capable GUI, more akin to an actual editor as opposed to just simply visualising data.
However, the issue I see with extending the GUI is that it is simply a hard thing to do. Personally, both QML and Lite are at the tip of my knowledge in user interface development. I believe we need a more efficient foundation to add more interactivity and features to either, something I’m simply not familiar with.
Having @mattiaslagergren onboard could propel things in this direction, but I am uncertain with how familiar you are with this level of complexity in desktop-land? It could potentially be built with web application tools, like Electron, similar to how QML is a client/server-type application.
I would ideally take someone on with experience in editor-style GUI development. Someone who could potentially consult in an appropriate direction and set guidelines for how to technically build up to a high enough level, without introducing brittleness. Also here, with @mattiaslagergren and c/o, that could potentially be possible.
Without assuming much, the most realistic option to me is the option-box approach. That is, many small GUIs working together, as opposed to one capable GUI, even though I’d personally prefer the latter.
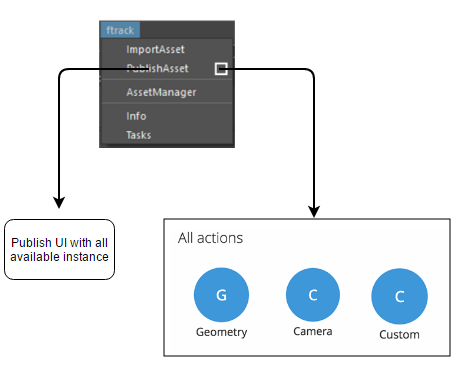
I understand it wasn’t clear from my image but the “Custom” option was actually intended as a “Full publish” option. This is further discussed here: Custom UI prototype
This has been a topic (electron vs python/qt) of discussion here at ftrack many times. We’ve a lot of experience writing UIs in different languages, but many of us tend to favour web frameworks and the fact that there are clear synergise with where our main ftrack web interface. That said, many of our customers and integrators are comfortable with python and qt UIs and we don’t want to put up a barrier for 3rd party developers.
All-in-all we’re leaning towards having a python/qt UI, but I expect there to be more discussions.
Hi there, I’m evaluating Pyblish and have the same question and I’m wondering if anything has changed since this thread was active. Apologies if this has been addressed and I missed it in the docs or a different thread (or even this one!). I assume it would be in the Pyblish-QML if anywhere.
My use case here is that I’m not looking to build a whole pipeline in one go, but instead develop over time a family of small individual publishing tools with their own UIs before the Pyblish window is shown.
For example, my first two tasks are individual tools which will:
publish cameras from Maya scenes
publish shelf buttons from specific shelves in the Maya UI
As you can see, being unable to filter the UI will give a lot of irrelevant info at publishing time (the shelf collectors will collect 50+ instances) and I’m not sure I see an elegant way to avoid it.
Thanks Marcus, Targets looks like the thing to try. The api docs don’t have register_target listed yet, but I assume there’s a deregister_target to go with it?
Also, while looking there, it occurred to me it might be even better to use the host feature i.e. register_host("maya.shelf_exporter") or register_host("maya.camera_toolset") or is that a bad idea?