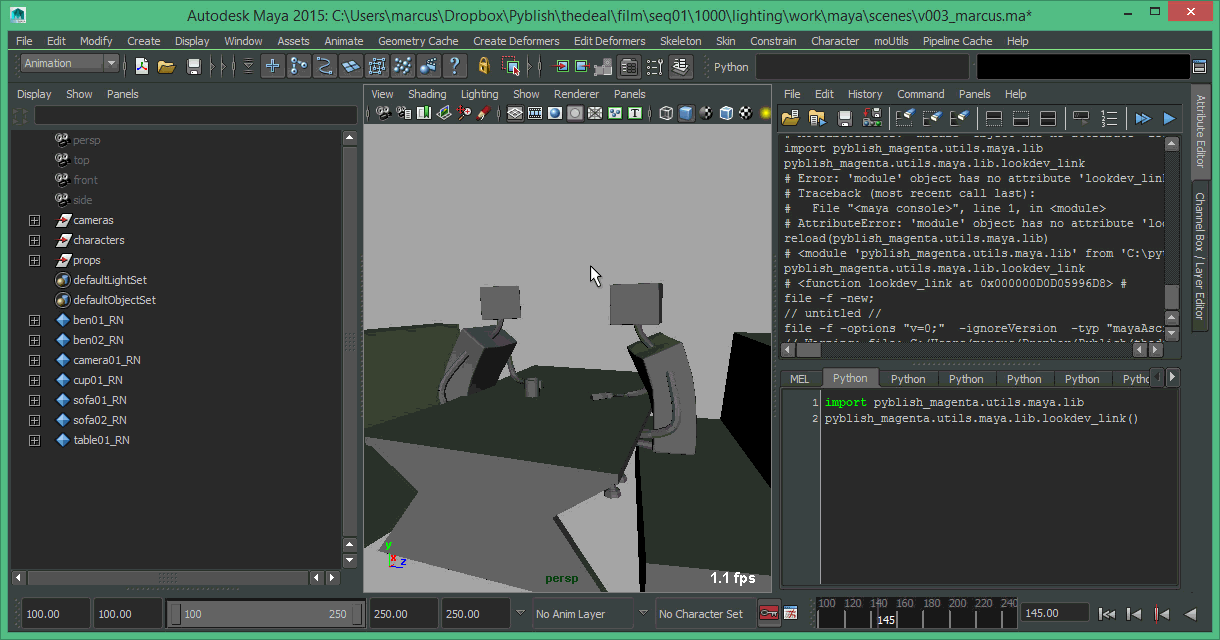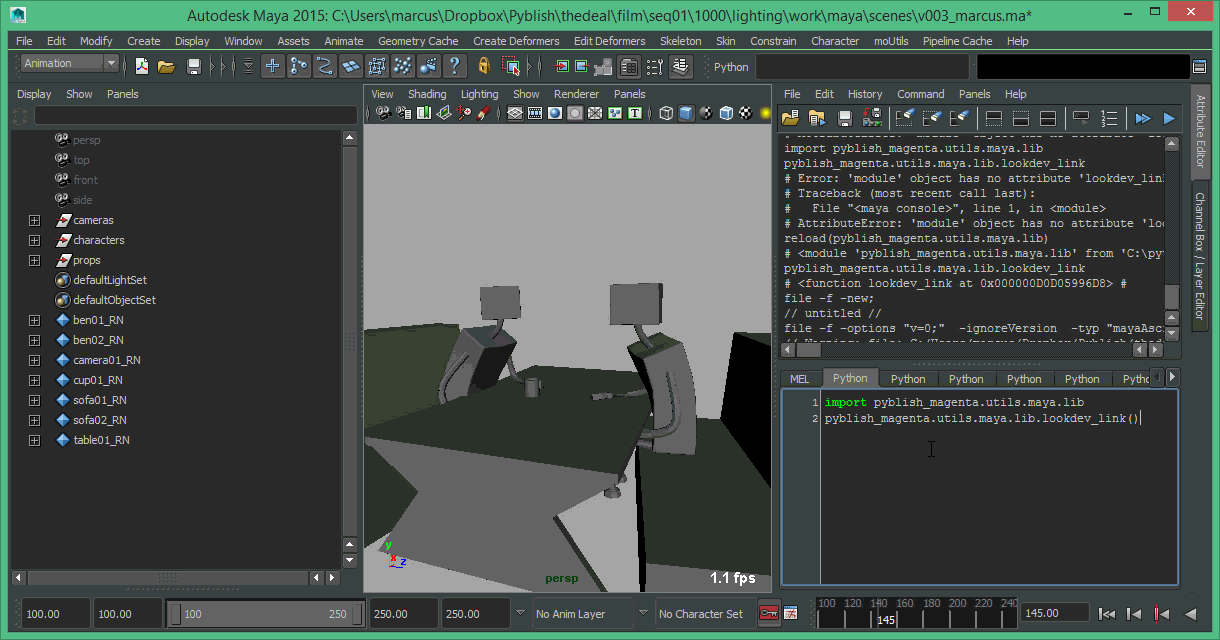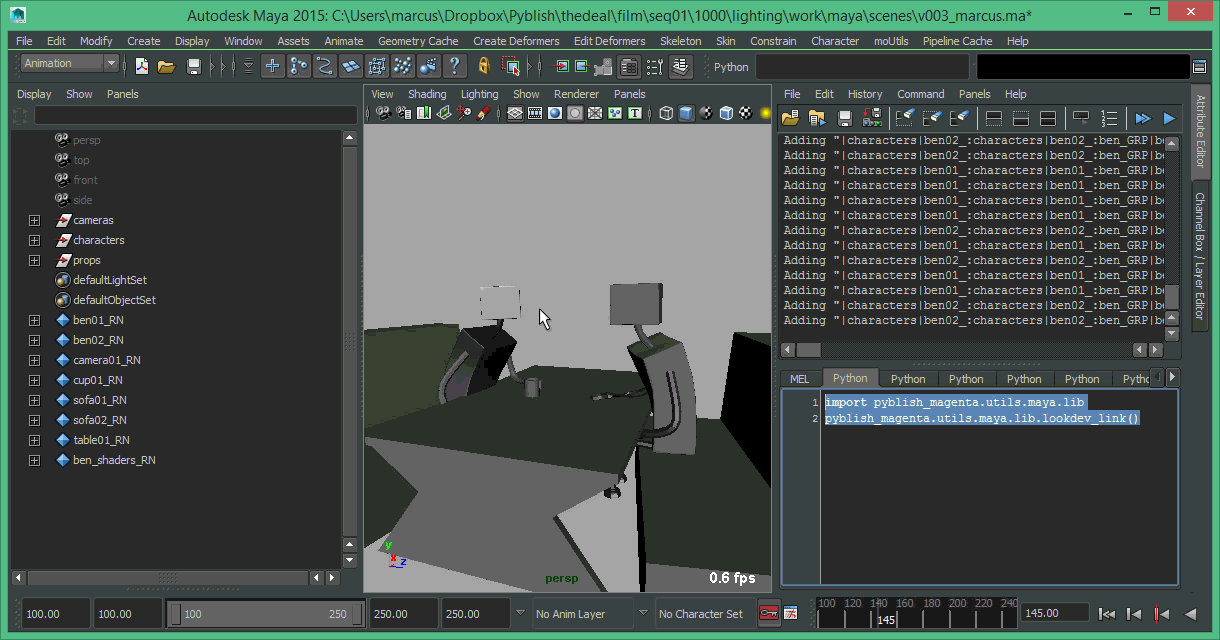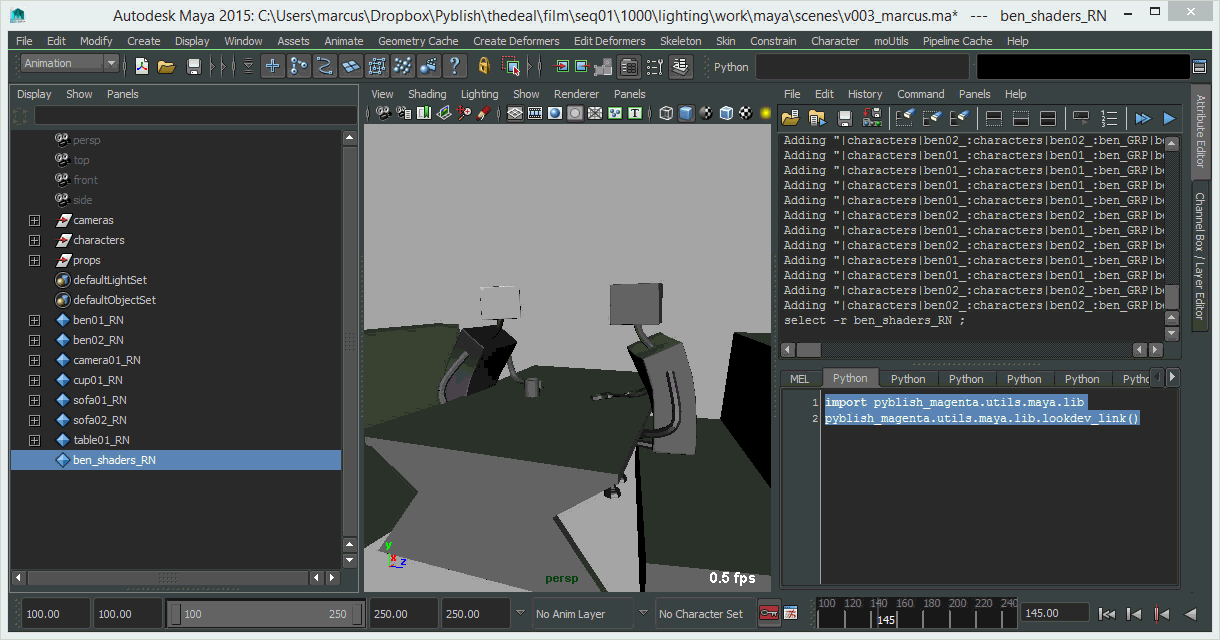
Is it that simple? 
Sure, an issue with Magenta I think, for starters.
Is it that simple?
Sure, an issue with Magenta I think, for starters.
Lighting is where the pipeline can truly start to show it’s colors.
It involves:
The workflow for a lighter is to…
It’s the “associated” part which is tricky.
It means that we’ll somehow need to determine where to find the shaders associated with a pointcache.
__________________________________________________________________
| |
| \thedeal\film\seq01\1000\animation\publish\v009\pointcache\ben01 |
|_________________________.________________________________________|
.
.
_________________________.____________________________
| v |
| \thedeal\assets\ben\lookdev\publish\v029\lookdev\ben |
|______________________________________________________|
The problem is…
ben01 has no natural connection to ben the asset.The asset was imported and used by the animator who produced the pointcache, but when publishing, this information was lost.
That is, there is no tracking of history nor relationships between assets.
To fix this, we’ll need to (1) publish additional information from the scene. Here is what something like that could look like from look development.
origin.json
{
"author": "marcus",
"date": "2015-08-17T12:57:11.636000Z",
"filename": "C:\\Users\\marcus\\Dropbox\\Pyblish\\thedeal\\assets\\ben\\lookdev\\work\\maya\\scenes\\v002_marcus.ma",
"item": "ben",
"project": "thedeal",
"references": [
{
"filename": "C:/Users/marcus/Dropbox/Pyblish/thedeal/assets/ben/modeling/publish/v012/model/ben/thedeal_ben_modeling_v012_ben.ma",
"item": "ben",
"project": "thedeal",
"task": "modeling"
}
],
"task": "lookdev"
}
(2) This file is then included with each published version.
\thedeal\film\seq01\1000\animation\publish\v009\pointcache\ben01
\thedeal\film\seq01\1000\animation\publish\v009\metadata\origin
(3) Such that we can look at the cache, and determine it’s origin.
\thedeal\assets\ben\lookdev\publish\v015\rigging\ben
(4) With the origin, it’s trivial to find the root asset and work our way up to where the latest version of the look development files are located.
\thedeal\assets\ben\lookdev\publish\v029\lookdev\ben
Here’s an example of what it can look like, with the shader relations from above, but without tracking.
import json
from pyblish_magenta.utils.maya import lsattrs
fname = r"%PROJECTROOT%/assets/ben/lookdev/publish/v014/lookdev/ben/thedeal_ben_lookdev_v014_ben.json"
fname = os.path.expandvars(fname)
with open(fname) as f:
payload = json.load(f)
for sg in payload:
shading_group = lsattrs({"uuid": sg["uuid"]})[0]
for m in sg["members"]:
member = lsattrs({"uuid": m["uuid"]})[0]
print("Adding \"%s\" to \"%s\"" % (member, shading_group))
cmds.sets(member, forceElement=shading_group)
It’s the fname we need to figure out automatically, based on the current file which is from lighting.
Edit: actually, I never posted an example of the shader relations.
Here’s what that looks like.
lookdev.json
[
{
"name": "lightMetal_SG",
"uuid": "f7b112ad-90bf-4274-8329-19a02092a083",
"members": [
{
"name": "|:ben_GRP|:L_leg_GEO",
"uuid": "53470dac-3709-499d-a490-4b8003b178ee",
"properties": {
"subdivision": 2,
"displacementOffset": 0.94,
"roundEdges": false,
"objectId": "f35"
}
},
{
"name": "|:ben_GRP|:R_arm_GEO",
"uuid": "8048064a-f6e0-48d4-bd03-e45b13dd2526"
},
{
"name": "|:ben_GRP|:neck_GEO",
"uuid": "53470dac-3709-499d-a490-4b8003b178ee"
}
]
},
{
"name": "orangeMetal_SG",
"uuid": "f7b112ad-90bf-4274-8329-19a02092a083",
"members": [
{
"name": "|:ben_GRP|:body_GEO.f[22:503]",
"uuid": "8048064a-f6e0-48d4-bd03-e45b13dd2526"
}
]
}
]
In which each Mesh is associated to a Shading Group via a UUID, generated via Python standard library uuid.uuid4() and applied during scene saved.
Hey @BigRoy, I’m looking to augment the schema with some additional information.
# From
pattern: '{@shot}/{task}/publish'
# To
pattern: '{@shot}/{task}/publish/{version}/{family}/{instance}/{file}'
But I’m having trouble… Is is possible to do what, without breaking anything? Where else can I add this information?
Currently no. Lucidity doesn’t support partial formatting/parsing so couldn’t list us the available versions in the integrator based on only this pattern. We need to be able to perform a partial format to list the currently available versions before we can choose what our next version will be.
A workaround for now would be to add another pattern with the full filepath and keep this shorter one (up to the version) available for the partial formatting in the Integrator.
Ok, that works.
I’ve pushed a first draft of the automatic shader assignment to Lighting from LookDev, here are some thoughts.
Here is the look development scene.

There a series of faces in the center of the model applied, to simulate face assignment in general.
And here are the shaders applied.
As we can see, the face assignment isn’t quite there yet, but otherwise things are looking good. Currently, it can:
From an artists point of view, the process is fully automatic once having imported the pointcaches. But, things aren’t quite so rosy, and here’s why.
import json
import pyblish_magenta.schema
from pyblish_magenta.utils.maya import lsattrs
lsattrs is amazing. This would have been amazingly difficult without it.
It’s interface involves passing a dictionary of key/values from which all nodes in the scene is compared against. Any node with a matching key/value is returned.
For us, this is great, because every node in the scene is uniquely identified by a Universally Unique Identifier.
This is so that:
Regardless of hierarchy or namespace, the mesh remains unique across all sessions. This is how we can build the lookdev.json from above where the "name" key is merely for debugging.
schema = pyblish_magenta.schema.load()
The schema is loaded, as we need to go from the absolute path of a referenced pointcache to it’s original asset; such as /ben01_pointcache -> /ben.
origins = dict()
for reference in cmds.ls(type="reference"):
if reference in ("sharedReferenceNode",):
continue
filename = cmds.referenceQuery(reference, filename=True)
# Determine version of reference
# NOTE(marcus): Will need to determine whether we're in a shot, or asset
data = schema["shot.full"].parse(filename)
Each reference in the scene is assumed to be an Instance and each instance is parsed into it’s components, project, task and item such that we can rebuild this into another location.
In this case, we’re rebuilding the path to a pointcache to an origin asset.
version = data["version"]
# Reduce filename to the /publish directory
template = schema["shot.publish"]
data = template.parse(filename)
root = template.format(data)
versiondir = os.path.join(root, version)
origindir = os.path.join(versiondir, "metadata", "origin").replace("/", "\\")
if not os.path.exists(origindir):
continue # no origin
originfile = os.path.join(origindir, os.listdir(origindir)[0])
if not originfile in origins:
with open(originfile) as f:
origins[originfile] = json.load(f)
origin = origins[originfile]
if not origin["references"]:
continue # no references, no match
reference = origin["references"][0]
template = schema["asset.publish"]
data = {
"asset": reference["item"],
"root": data["root"],
"task": "lookdev"
}
assetdir = template.format(data)
The origin asset has been built, based on the origin.json we’ve published alongside the asset. Now we need to get the latest version from lookdev and import it.
# NOTE(marcus): Need more robust version comparison
version = sorted(os.listdir(assetdir))[-1]
instancedir = os.path.join(assetdir, version, "lookdev", reference["item"])
# NOTE(marcus): Will need more robust versions of these
shaderfile = next(os.path.join(instancedir, f) for f in os.listdir(instancedir) if f.endswith(".ma"))
linksfile = next(os.path.join(instancedir, f) for f in os.listdir(instancedir) if f.endswith(".json"))
# Load shaders
# NOTE(marcus): We'll need this to be separate, at least functionally
namespace = "%s_shaders_" % reference["item"]
if namespace not in cmds.namespaceInfo(
":", recurse=True, listOnlyNamespaces=True):
cmds.file(shaderfile, reference=True, namespace=namespace)
And it’s been imported. With a lot of assumptions.
The final step is actually assigning shader to mesh, by way of their UUIDs.
with open(linksfile) as f:
payload = json.load(f)
for shading_group_data in payload:
try:
shading_group_node = lsattrs({"uuid": shading_group_data["uuid"]})[0]
except:
# This would be a bug
print("%s wasn't in the look dev scene" % shading_group_data["name"])
continue
for member_data in shading_group_data["members"]:
try:
member_node = lsattrs({"uuid": member_data["uuid"]})[0]
except:
# This would be inconsistent
print("%s wasn't in the lighting scene" % shading_group_data["name"])
continue
print("Adding \"%s\" to \"%s\"" % (member_node, shading_group_node))
cmds.sets(member_node, forceElement=shading_group_node)
Aside from missing face assignment, there are a few things brittle about this approach.
origin instance was published (with no graceful handling in case we are wrong)Ok, so that’s all great. Now…
It may not look like much, but the above problems are mere technicalities and cosmetics in comparison to this. This is major pipeline functionality, without which we would have little luck in developing anything useful.
An api would solve this by allowing something like:
ls(data)
This would list all possible locations present for the data.
Where the data is a dictionary holding the least amount of data that the pipeline requires to define where the published file would be. In short it would be its identifier.
identifiers = {'asset': 'ben', 'task': 'lookdev', 'family': 'shader', 'version': 14}
The API could either use a Schema (eg. with lucidity) to format where the file would be or use something like Open Metadata along with cQuery to query that. Then the pipeline would also allow us to retrieve possible values when we only have a subset of the required data. For example when listing what versions are available and limit it to no further queries than which define the limited key. This would solely be an optimization, but with the amount of content that could be in a version (or an asset?) potentially a required one:
identifier = {'asset': 'ben', 'task': 'lookdev', 'family': 'shader'}
values = ls(identifier, limit='version')
Thinking about it now it could return the available identifiers that were found:
query_identifier = {'asset': 'ben', 'task': 'lookdev', 'family': 'shader'}
identifiers = ls(query_identifier, limit='version')
print identifiers
# [ {'asset': 'ben', 'task': 'lookdev', 'family': 'shader', 'version': 1},
# {'asset': 'ben', 'task': 'lookdev', 'family': 'shader', 'version': 2},
# {'asset': 'ben', 'task': 'lookdev', 'family': 'shader', 'version': 3},
# {'asset': 'ben', 'task': 'lookdev', 'family': 'shader', 'version': 4},
# {'asset': 'ben', 'task': 'lookdev', 'family': 'shader', 'version': 5}]
To get the highest version:
highest_version = max(identifiers, key=lambda x: x['version'])
And to find the path for that specific data:
path = ls_path(highest_version)
This same method could be used in the Integrator to define the correct output path based on the data that is valid upon extraction. This means we’ll use the same interface for defining an extraction point as we’ll use for collection/searching.
Actually we would need three methods parse, format and ls.
Parse would allow us to retrieve the identifiers from a path. This should retrieve as much identifiers as it can as opposed to what lucidity does by default which is returning the first match found. This would mean from any file it would know what it is.
Format would use a dictionary of identifiers to calculate a path. Preferrably 100% of the paths retrieved and created should be using this interface to ensure the file is where it should.
Ls would take a dictionary of identifiers and returns all available identifiers contained within it.
Would these three ensure that we’d be able to find where and what a file is?
These different methods could be implemented in different ways, e.g. schema vs schemaless. Yet the interface should be minimal and it seems this would provide all information to define file locations. If all our plug-ins would solely use this api it means the underlying system (schema vs schemaless) could be swapped by only implementing these three methods.
Sounds like it, but it also sounds a little magical.
For example, where does the root come from? And what about directories in-between the various data points, such as /publish inbetween /model and /v001?
Perhaps a prototype could help convey it’s benefits and better articulate it’s potential?
Found an issue with the above UUID approach in regards to face assignment.
Currently, (1) a mesh is assigned a UUID and (2) associated with a shading group. The information is stored like this.
{
"shadingGroup uuid": {
"members": ["mesh1 uuid", "mesh2 uuid"]
}
}
The lookup then takes the form of:
matches = lsattrs({"uuid": "mesh1 uuid"})
But where are the faces? The UUID is assigned to the mesh node itself, not to the faces, so this information is lost.
The lookdev.json above will need an additional member; components.
That’s correct.
Since the component isn’t an attribute on the node that would of course be a separate query. We do it like this (pseudocode):
for member in members:
matches = lsattrs({"uuid": member['uuid']})
# If the member has component add it to the node name
components = member['components']
if components:
matches = ['{0}.{1}'.format(node, components) for node in matches]
cmds.sets(matches, forceElement=shading_group)
I’m not following this thread, but saw you were having problems with face assignments here.
I would say that it is not just face assignments that’ll be a problem, but there are other attributes you can be setting up in the lookdev file. What we usually do, is to import/reference the pointcaches and get the lookdev to use that point cache rather than trying to copy all the lookdev configuration to the point cache.
Good question.
This is also what somewhat confuses me, because in reality /publish is a different place than /work. So if you’d want to differentiate between these two locations you would have to identify this difference, thus add it to the identifier. Unless it’s hardcoded to choose one folder over the other, so you would never access work and only access publish.
This same difference is actually between our film and assets folder. There should be something that ‘identifies’ it as being different, otherwise the difference could never be made.
The opposite would be to iterate the folders and guess that something with name or metadata X is actually your asset no matter where it is. Yet since it wouldn’t know where to look you’d always iterate a full project. Even if you’d know where the asset is you’d need to identify whether you’re accessing the work or publish folder if you’re differing between those.
What’s your idea?
Thanks for sharing, it sounds like what we’re doing too, but let me just see if I get this straight.
In your case:
@tokejepsen Not entirely sure what you mean here. But we’re separating lookdev and lighting.
Lookdev is the designing of textures and shader setup for an asset. This would also hold custom attributes or displacement sets (like vray attributes or vray object properties nodes) and we’re exporting this data into our own format. Basically within the lighting scene we would recreate the exact conditions.
Actually we’re already exporting this additional data if I’m correct.
lighter assigns the pointcache to the meshes.
Would be great if you can recreate is exactly. Its something I have been chasing for a long time, but could never account for all the attributes and setup. That’s why I’ve always resorted to applying the point cache to the lookdev mesh.
Ah yes. So what I assume you’re doing is you load in the lookdev mesh and apply the deformations of the mesh by applying the ‘pointcache’ onto that lookdev mesh. So the pointcache that is loaded is not a new mesh being created in the scene, but only the deformations are loaded onto the pre-existing mesh.
Are you using Alembics for this? Or another format?
Technically I reference in the Alembic point cache, and the lookdev mesh. I connect the Alembic deformation to the lookdev mesh by attributes, copy the transform values and in some cases setup a live blendshape.
Never liked this workflow, but it has served me well on a couple of projects now. The good thing about it, is you can just replace the Alembic reference with a newer animation file, and everything is preserved.
You’re referencing the Alembic file directly? That’s great to hear; we jumped through some hoops wrapping the alembic cache with a Maya scene, and referencing that instead, because of some bugs @BigRoy had noticed.
The only major issues are that you need to have the Alembic plugin loaded on startup, and when you are pushing to a render farm.
A userSetup.py that loads the plugin quitely, seems to solve it for me.