Ok, that works.
Asset Linking
I’ve pushed a first draft of the automatic shader assignment to Lighting from LookDev, here are some thoughts.
Here is the look development scene.

There a series of faces in the center of the model applied, to simulate face assignment in general.
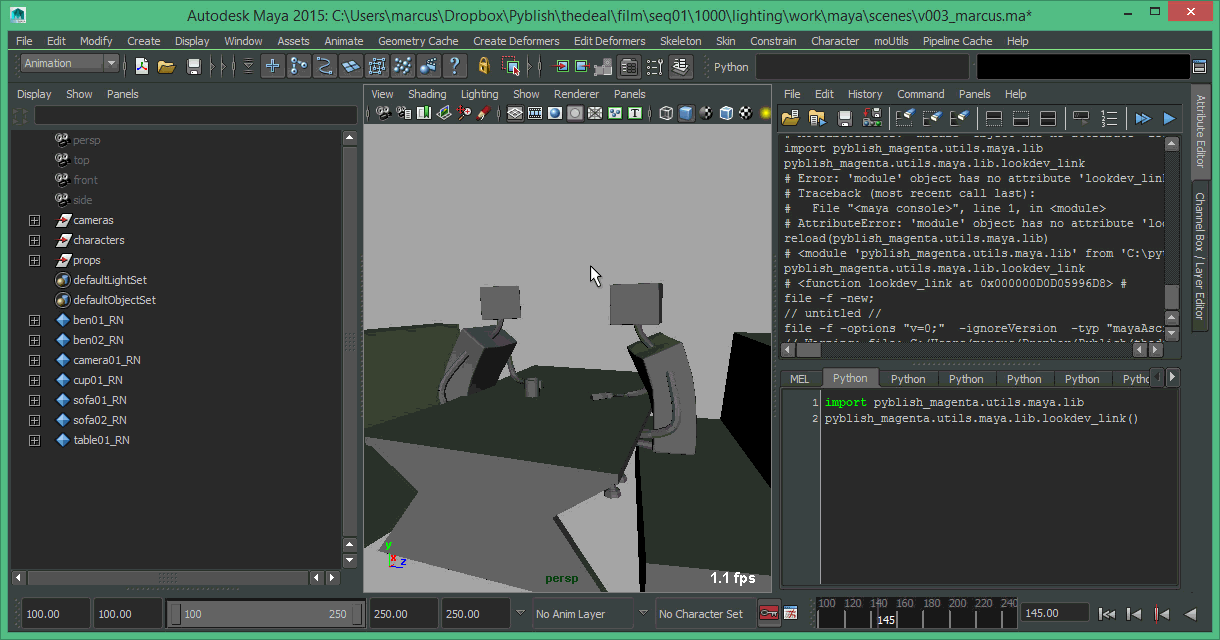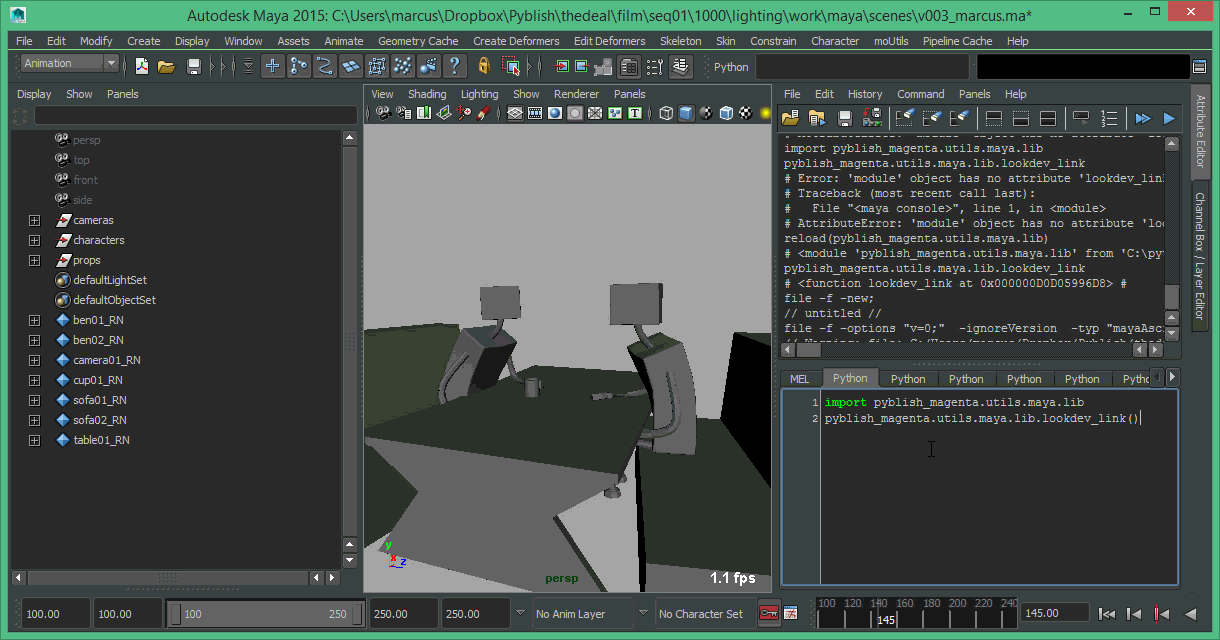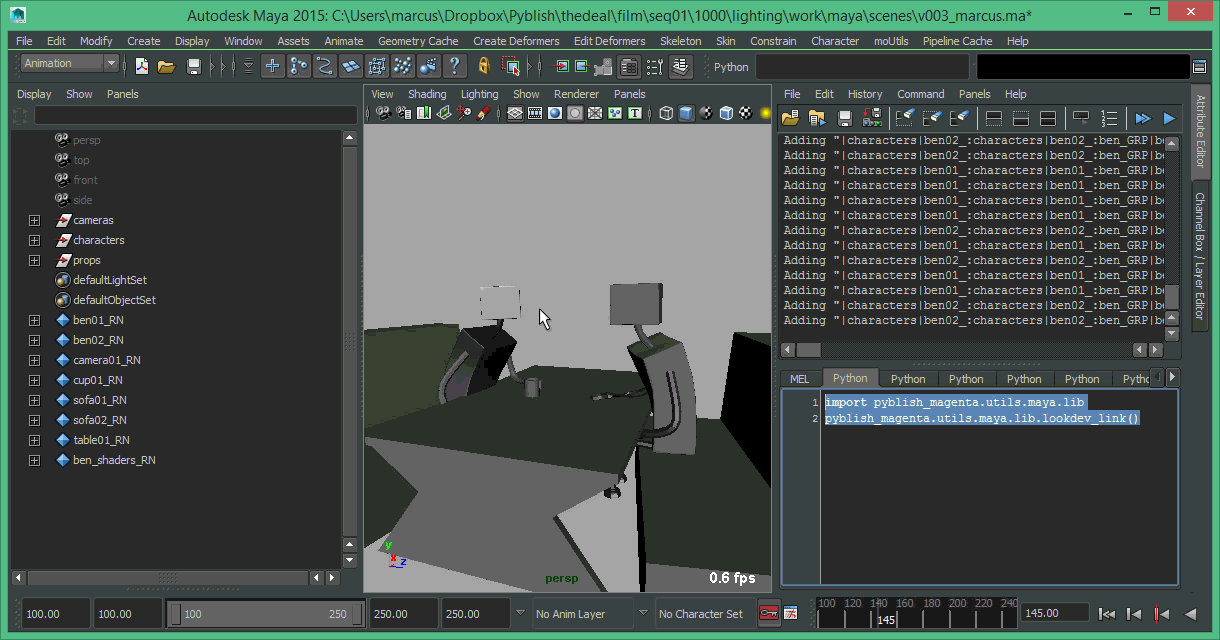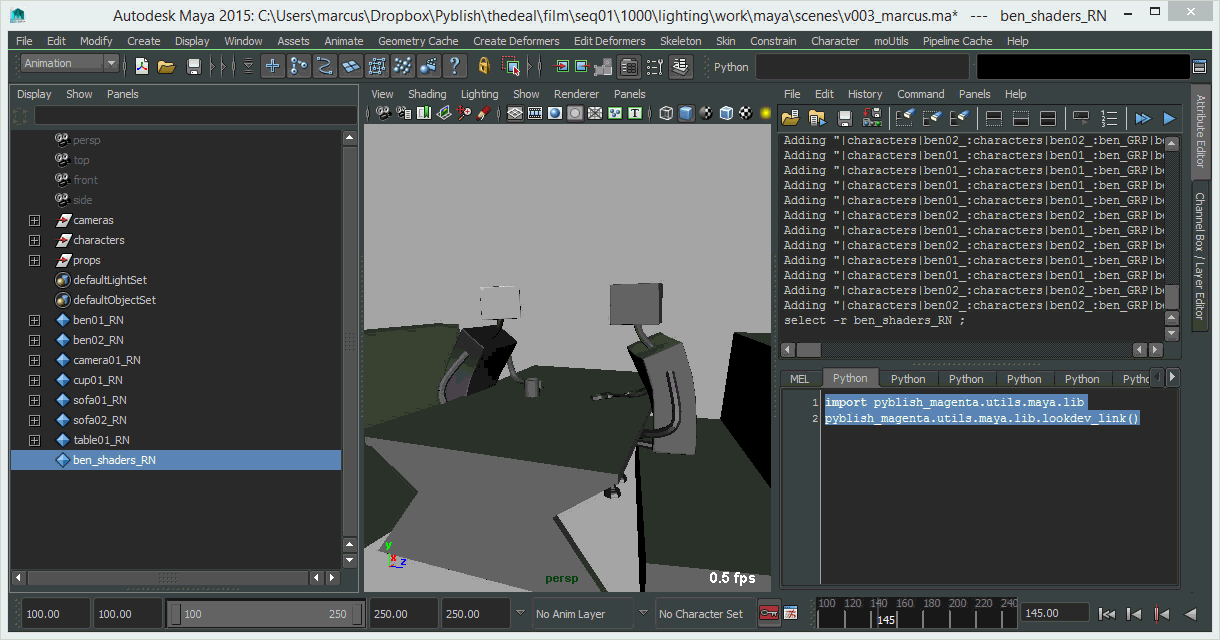
And here are the shaders applied.
As we can see, the face assignment isn’t quite there yet, but otherwise things are looking good. Currently, it can:
- Look up the origin of each referenced pointcache
- Deduce the look development shaders
- And links between shaders and meshes
- Apply these shaders to the pointcached meshes
From an artists point of view, the process is fully automatic once having imported the pointcaches. But, things aren’t quite so rosy, and here’s why.
The Code, In Pieces
import json
import pyblish_magenta.schema
from pyblish_magenta.utils.maya import lsattrs
lsattrs is amazing. This would have been amazingly difficult without it.
It’s interface involves passing a dictionary of key/values from which all nodes in the scene is compared against. Any node with a matching key/value is returned.
For us, this is great, because every node in the scene is uniquely identified by a Universally Unique Identifier.
This is so that:
- The identity of a polygonal mesh from modeling can be recorded
- And associated with a shader
Regardless of hierarchy or namespace, the mesh remains unique across all sessions. This is how we can build the lookdev.json from above where the "name" key is merely for debugging.
schema = pyblish_magenta.schema.load()
The schema is loaded, as we need to go from the absolute path of a referenced pointcache to it’s original asset; such as /ben01_pointcache -> /ben.
origins = dict()
for reference in cmds.ls(type="reference"):
if reference in ("sharedReferenceNode",):
continue
filename = cmds.referenceQuery(reference, filename=True)
# Determine version of reference
# NOTE(marcus): Will need to determine whether we're in a shot, or asset
data = schema["shot.full"].parse(filename)
Each reference in the scene is assumed to be an Instance and each instance is parsed into it’s components, project, task and item such that we can rebuild this into another location.
In this case, we’re rebuilding the path to a pointcache to an origin asset.
version = data["version"]
# Reduce filename to the /publish directory
template = schema["shot.publish"]
data = template.parse(filename)
root = template.format(data)
versiondir = os.path.join(root, version)
origindir = os.path.join(versiondir, "metadata", "origin").replace("/", "\\")
if not os.path.exists(origindir):
continue # no origin
originfile = os.path.join(origindir, os.listdir(origindir)[0])
if not originfile in origins:
with open(originfile) as f:
origins[originfile] = json.load(f)
origin = origins[originfile]
if not origin["references"]:
continue # no references, no match
reference = origin["references"][0]
template = schema["asset.publish"]
data = {
"asset": reference["item"],
"root": data["root"],
"task": "lookdev"
}
assetdir = template.format(data)
The origin asset has been built, based on the origin.json we’ve published alongside the asset. Now we need to get the latest version from lookdev and import it.
# NOTE(marcus): Need more robust version comparison
version = sorted(os.listdir(assetdir))[-1]
instancedir = os.path.join(assetdir, version, "lookdev", reference["item"])
# NOTE(marcus): Will need more robust versions of these
shaderfile = next(os.path.join(instancedir, f) for f in os.listdir(instancedir) if f.endswith(".ma"))
linksfile = next(os.path.join(instancedir, f) for f in os.listdir(instancedir) if f.endswith(".json"))
# Load shaders
# NOTE(marcus): We'll need this to be separate, at least functionally
namespace = "%s_shaders_" % reference["item"]
if namespace not in cmds.namespaceInfo(
":", recurse=True, listOnlyNamespaces=True):
cmds.file(shaderfile, reference=True, namespace=namespace)
And it’s been imported. With a lot of assumptions.
The final step is actually assigning shader to mesh, by way of their UUIDs.
with open(linksfile) as f:
payload = json.load(f)
for shading_group_data in payload:
try:
shading_group_node = lsattrs({"uuid": shading_group_data["uuid"]})[0]
except:
# This would be a bug
print("%s wasn't in the look dev scene" % shading_group_data["name"])
continue
for member_data in shading_group_data["members"]:
try:
member_node = lsattrs({"uuid": member_data["uuid"]})[0]
except:
# This would be inconsistent
print("%s wasn't in the lighting scene" % shading_group_data["name"])
continue
print("Adding \"%s\" to \"%s\"" % (member_node, shading_group_node))
cmds.sets(member_node, forceElement=shading_group_node)
What’s broken?
Aside from missing face assignment, there are a few things brittle about this approach.
- I’m assuming we’re in a shot, as opposed to an asset, which is ok most of the time as you are most likely to apply shaders from lookdev during shot production
- I’m formatting a path with it’s own parsed equivalent to find a parent path
- I’m assuming the location of where the
origin instance was published (with no graceful handling in case we are wrong)
- I’m assuming the name of this origin file, based on it’s extension
- I’m assuming a lookdev scene has only a single reference
- I’m comparing versions ad-hoc; there’s no guarantee this v-prefixed variant will last, and if it changes, tough luck.
- I’m assuming the shaders are located in a Maya Ascii file, the only Maya Ascii file present in the published version.
- File loading is embedded into this one giant function
- I’m being very forgiving regarding what is assigned a shader, and what is not, without any graceful handling of problems.
Ok, so that’s all great. Now…
What works?
- The linkage between a shader and mesh? Check!
- Publishing “origin” information from every asset automatically? Check!
- Inferring an original asset from a pointcache? Check!
It may not look like much, but the above problems are mere technicalities and cosmetics in comparison to this. This is major pipeline functionality, without which we would have little luck in developing anything useful.


 could be
could be