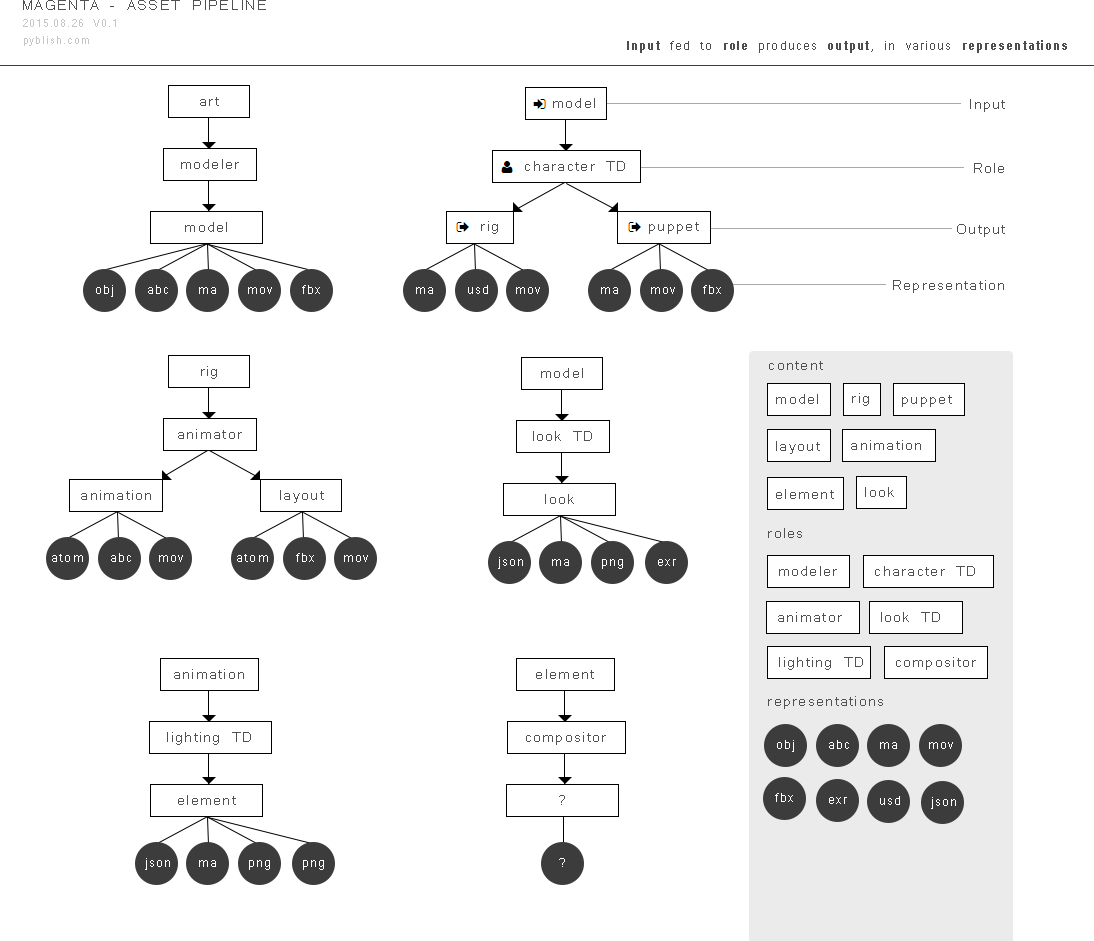
Ok. Looking at the length of this reply it’s to show this is an interesting, but also easily confusing topic.
First, I think you misidentify between content and role oriented. To be more correct with the terms we’re currently working “Task oriented”. That I’m misunderstanding what you’re trying to explain even more shows that this is something that’s confusing and easily misunderstood. This is how I see that terminology make sense:
Content oriented
If the structure wouldn’t be role oriented the outputs would be joined together outside of their tasks. A pure “Content” based structure I think would be (at the very core):
{item}/published/{content}/{version}
So all tasks/roles would produce different content so their content can easily go together. Personally I would never do this.
Task oriented
I think where we want to go is to a place where any Task can have any output. Workflows differ and requirements change over time. I think assumptions will have to made about what Task produces relevant output for another Task (eg. “Model” task creating output relevant for “lookdev”).
Also making this “no assumptions” means it allows re-use of similar plug-ins across multiple tasks. Or even separate for a complex asset into “lowres_model” and “highres_model” task.
XXX oriented
So yes, it seems there’s much here that can confuse someone. To be complete this how if I feel we’re currently doing our structuring:
- Task/Instance/Content/Version
Where Content is family. Yet there might be a lot of different Instances that contain very different data, some might have renders… others might not. Purely looking at the outputs of a folder (eg. looking in `published/) would mean we won’t be able to identify directly if it produced any videos whatsoever, or any models or renders.
Therefore it might make more sense to do it differently, especially from an Artist’s perspective. Someone looking for specific content would likely know less about the instances as he searches for content, but more about what type of content he’s searching.
For example assembling your compositing scene might involve looking for all renders that are available. So you look up the family renders. And you figured you’d need the cached camera as well. You might find it quicker if you’re looking for the family camera that has all instances then when you’re looking for an instance of the camera by name.
Similarly if you’d want to load an alembic into your comp you would search for the cache (or pointcache?) first before anything else.
So this might make more sense:
- Task/Content/Instance/Version
Some examples would be:
ben/modeling/published/model/ben_hires/v01
ben/modeling/published/model/ben_hires/v02
ben/modeling/published/model/ben/v01
The danger here becomes if one instance produces multiple families you get into the same instance being in duplicate places. For example, let’s add some extra outputs:
ben/modeling/published/model/ben_hires/v01
ben/modeling/published/model/ben_hires/v02
ben/modeling/published/model/ben/v01
ben/modeling/published/metadata/ben_hires/v01
ben/modeling/published/review/ben_hires/v01
Yet since we’re decoupling how closely review and model are linked (since they are not of the same version) this also makes me believe it’s more likely those will be different instances anyway:
ben/modeling/published/review/ben_turntable/v01
ben/modeling/published/review/ben_faceTurntable/v01
And whenever something needs to be directly linked, thus having a perfect one-to-one relationship this means they are the same family. Let’s say a model should always specify it’s geometry specs in text-format this would mean you’d extract it within model/ben_hires/v01.
Separating by content
Separating solely based on extension will set you up for failure. Sometimes there’s need to separate content in two similar datatype files (which in majority of cases would be its own instance or even a separate task):
- A rig could be baked differently depending on whether it’s cached for use in a game-engine as opposed to one where it’s used for a render within (for example) Maya, both outputs could still be .ma (or both .fbx)
- Some content could be separated into ‘chunks’ to allow a partial import elsewhere. (This is probably more fit to be a separate ‘instance’ of the output data.
Or they can even have different datatypes with similar extensions
- A gpuCache and Alembic are both .abc files for the same source content but different output structure.
So I think separating the file by name to identify its contents is a big plus (if not a must). This is in line with how we want to have “clearer” filenames to show some what data they hold. We’ve also seen that doing this can create too long names and not doing it has its own unavoidable errors as well; a middleground will likely be taken here.
Just as a note I think this is a clear structure:
{item}/{task}/published/{instance}/{family}/{version}/<files here>
In the case of a model of our character Ben being published in the modeling task this would format to something like:
ben/modeling/published/ben/model/v01/ben_model_v01.ma
Note that I would think a shaderRelations.json is a similar family file as the shader itself. It has a one-to-one relationship with the shader file. They belong together, and as such always extract in one go together.
Similarly AOVs/renderElements belong with a renderLayer. (Here this relationship is even more present because they can be simply rendered into a single multichannel .exr). For example:
sh1000/lighting/published/masterLayer/render/v01/sh1000_masterLayer_v01_####.exr
Nevertheless if it would be rendered as separate .exr files, this would be:
sh1000/lighting/published/masterLayer/render/v01/sh1000_masterLayer_v01_beauty_####.exr
sh1000/lighting/published/masterLayer/render/v01/sh1000_masterLayer_v01_AO_####.exr
sh1000/lighting/published/masterLayer/render/v01/sh1000_masterLayer_v01_diffuse_####.exr