Just checking. You’re not necessarily saying to ditch having references in the scene, but more so that the artist doesn’t “reference” an something himself yet uses ready-to-go tools to do so. The assets being loaded would still be references? Or what are you aiming at?
Yeah, pure cosmetics at the moment, but consistent with how they are namespaced later, with the added {occurence}.
Good, I also want this.
Exactly.
Whenever transform values are preferable, you could use the animation curves, as opposed to the pointcache.
In cases where a pointcache would never be used, the pointcache instance could simply be de-toggled. But I’d like to encourage full output each time. Both points and animation.
That’s kind of what I’m saying. Not as an absolute either-or, but to have the option to. It basically boils down to my master plan involving shot-building, which we haven’t gotten to yet.
For now, all that matters is that we shouldn’t get too dependent on the fact that assets are Maya-referenced into a scene; for example, we don’t want to consider building upon offline edits directly for common tasks.
Could you elaborate briefly on this? Not sure what you mean.
It was just an example of something reference-specific. If we depend on reference edits in any way, we won’t be able to import assets into the scene as they won’t support that feature.
With reference from your reply in Publishing Renders for Lighting @BigRoy, the only other problem to be solved at this point is…
- How to format the innards of a
renderLayer?
For example, pointcaches, models, rigs etc are all formatted into the published directory, but they are also named appropriately. They include the project, topic and version.
When it comes to renderLayer, since we can’t be sure about exactly what is in there it can be difficult to format? For example, the render layer might have only one pass, a single sequence of images, in which case we can apply the same “formula” as we are with pointcaches and simply name the resulting files accordingly, appending the relevant frame number.
But if render layers also contain any of the other variables relevant to rendering, I’m not sure how to format this.
The alternative might be to not format it, but let whatever innards of that directory remain as-is, but then we would lose the benefit of an integration step and be forced to include schemas and formatting and such during extraction. Not good.
Another alternative, one I am reluctantly inclined to prefer, is to lock down a particular layout such that we can make strict assumptions about the innards of the render layer directory, until it has become clear what is missing or needs to loosen up.
Thoughts?
It’s hard to exactly pinpoint this because the format differs. And it differs a lot. In some case you render only a single layer (instance) and in others many. Sometimes there’s many passes or variables, and sometimes close to None. It’s this loose because it’s just required to be adaptive in a sense.
I think each instance should just transfer with its inner structure for Extraction/Integration (work -> publish). If a certain project, shot or a specific pipeline ends up having specific rules on the output format I’d say that’s up to adding a Validator to ensure their formatting is valid.
You’d likely want to validate these exact rules before rendering anyway, because there’s just too much output (taking long time to render) to have it mess up during rendering.
@tomhankins, what do you think is a way forward? Can we structure our render outputs and lock it down? Or do you require it to be less undefined?
The other open discussion point would still be the versions per instance.
We’re doing something similar to your second diagram here. We have a publish scripts that we can run through Deadline directly tho, which is sort of neat.
The script is quite simple. Too simple really. After a render is completed, we right click on the task in Deadline’s interface and choose to run our script. The script would check if the frame numbers matches what we have in Shotgun and then simply switch the shot’s status to “Ready for Comp”. Other wise, it just fails.
It doesn’t check anything else at the moment, just frame numbers.
I have a lot of idea for this, like, instead of needing manual execution, this job should be created as a dependent job under its corresponding render job. So it’d execute itself when the render is complete.
2 Likes
Is this using Pyblish’s power already? Or is it a single function running over the files?
We might be hopping into this with Magenta too. If you’re willing to hop in that would be great. It means we can work towards a setup that will work for Magenta but also for you based on your previous experience.
In short the idea is to:
- Set up a dependent job in Deadline
- That job runs a Pyblish job (could even be a task per frame so invalidations would even show in Deadline!)
- A report would be created based on the Validations.
The idea is that this runs the same steps of CVEI (Collect, Validate, Extract, Integrate). This would mean it would just be as easy to add additional Validators (like your frame number matching) or Extractor (maybe you’d want a ‘Slap Comp’ to be rendered if the frames passed a simple Validation).
instead of needing manual execution
Might be an idea to look into event plugins in Deadline for this. This is how the standard Shotgun and Ftrack integrations work. Even draft work like that.
2 Likes
Quick Overview of Current Workflow
Here’s a few summaries along with video of how assets are made with Magenta today.
The goal is to reduce and simplify the steps, both individually and as a whole.
Modeling
Description
-
Setup
A working directory is automatically created along with project-dependent environment variables used during publish. -
Create
Bulk of the artist work, does whatever is necessary to produce shareable model. -
Format
A hierarchy is created in accordance to Magenta convention; name of asset followed by “GRP” separated by an underscore. -
Integrate
Surrounding/related asset is referenced and matched to the model. This is how we can ensure that assets actually fit together. -
Add output
Additional outputs, in this case a turntable. -
Publish
Finally, run it through the tests and export it into an appropriate location.
Rigging
Description
-
Setup
A working directory is automatically created along with project-dependent environment variables used during publish. -
Reference
Source geometry is referenced into the scene for rigging. -
Rig
Bulk of an artist’s work; the rig is created. -
Format
Internal layout is formatted according to convention.
- Assembly named {asset}_GRP
- pointcache_SET contains all cachable geometry
- controls_SET contains all animatable controls
-
More output
Additional outputs, in this case a turntable. -
Validate
Run it through the tests, fix problems. -
Publish
Finally, share your work with others once tests all pass.
Look Development
Description
-
Setup
A working directory is automatically created along with project-dependent environment variables used during publish. -
Reference
Source geometry is referenced into the scene for shading. -
Shade
Bulk of an artist’s work; the model is shaded. -
Format
Internal layout is formatted according to convention.
- shaded_SET contains all shaded geometry
-
Publish
Finally, share your work with others once tests all pass.
Animation
Description
-
Setup
A working directory is automatically created along with project-dependent environment variables used during publish. -
Reference
Source rigs are referenced into the scene for animation. -
Layout
Rigs are laid out in the scene, according to storyboards/animatic. -
Animate
Rigs are animated -
Publish
Finally, share your work with others once tests all pass. Note that there is no formatting required, formatting inherited from rigs.
Lighting
Description
-
Setup
A working directory is automatically created along with project-dependent environment variables used during publish. -
Reference
Source pointcaches are referenced into the scene for lighting. -
Assign
Shaders from look development are automatically deduced from source pointcaches and assigned from their latest versions. -
Light
Scene is lit -
Render
Scene is rendered -
Publish
Not finished
1 Like
Transposed Version in Hierarchy
As we talked about in the thread on publishing for lighting, I’ve made an attempt at moving the version under each Instance, as opposed to above where it was previously.
This means:
-
Instance's can now be published and incremented individually, which then also means… -
Instance's no longer maintain a connection to each other
This connection is what has thus far been used to link, say, a Quicktime to a Rig, the Quicktime representing the rig in a format compatible with media players.
# Example
publish
▾ v001
▾ rig
▸ ben.ma
▾ review
▸ turntable.mov
The link was made by instances residing in a common version directory, which is now no longer the case.
publish
▾ rig
▾ ben
▸ v001
▾ review
▾ ben
▸ v001
The benefit of course being that we can now update individual instances in shots, such as an individual render layer or animation of a character, without actually having to either publish everything at once, or somehow linking missing Instance's to their closest available version.
Formalism
With this new approach, it’s easy to get lost in translation (I know I am) so I figured I’ll provide some formal, high-level labelling on the object model and methodology currently employed in Magenta.
Content Orientation
The workflow as it exists today is content-oriented as opposed to role-oriented.
In role-orientation, tools are built upon the expertise present in an organisation, such as some being an animator, rigger, modeler, or lighter etc. Each role is fixed and it’s input/output determined by what is commonly associated with each role. For example a rigger isn’t expected nor supported to provide geometry just as a lighter isn’t usually meant to deliver character rigs.
The disadvantage of role-orientation is that roles change but pipelines don’t. A pipeline is like a rail-road track. It makes delivering a hundred similar shots easy, but does either nothing or harm to the odd ones out.
Conversely, content-orientation means facilitating the type of content that can be created within production and allowing anyone to contribute with any type of it without being limited by the particular sub-pipeline built for around their main expertise.
With this approach, a model is always a model no matter who publishes it and tools built around models work across the board. The same then applies to any other type of content.
Current types of content
modelriglookdevpointcachecurvesreview
Where each type is represented in Pyblish as a family. Types are currently a mixture of abstract content used by another artist and it’s physical representation on disk. For example, both pointcache and curves may be used by the lighter, even though they both refer to “animation” which is ultimately what the lighter is looking for, regardless of their representation.
Suggested types of content
-
model- Static points -
rig- Animation interface to static points -
puppet- Skeleton and relationships -
animation- Dynamic points -
layout- Content associated with a shot -
look- Shader network -
element- An individual image sequence (render layer)
And here’s their configuration with respect to which role typically produces the output given an input, along with a few proposed representations.
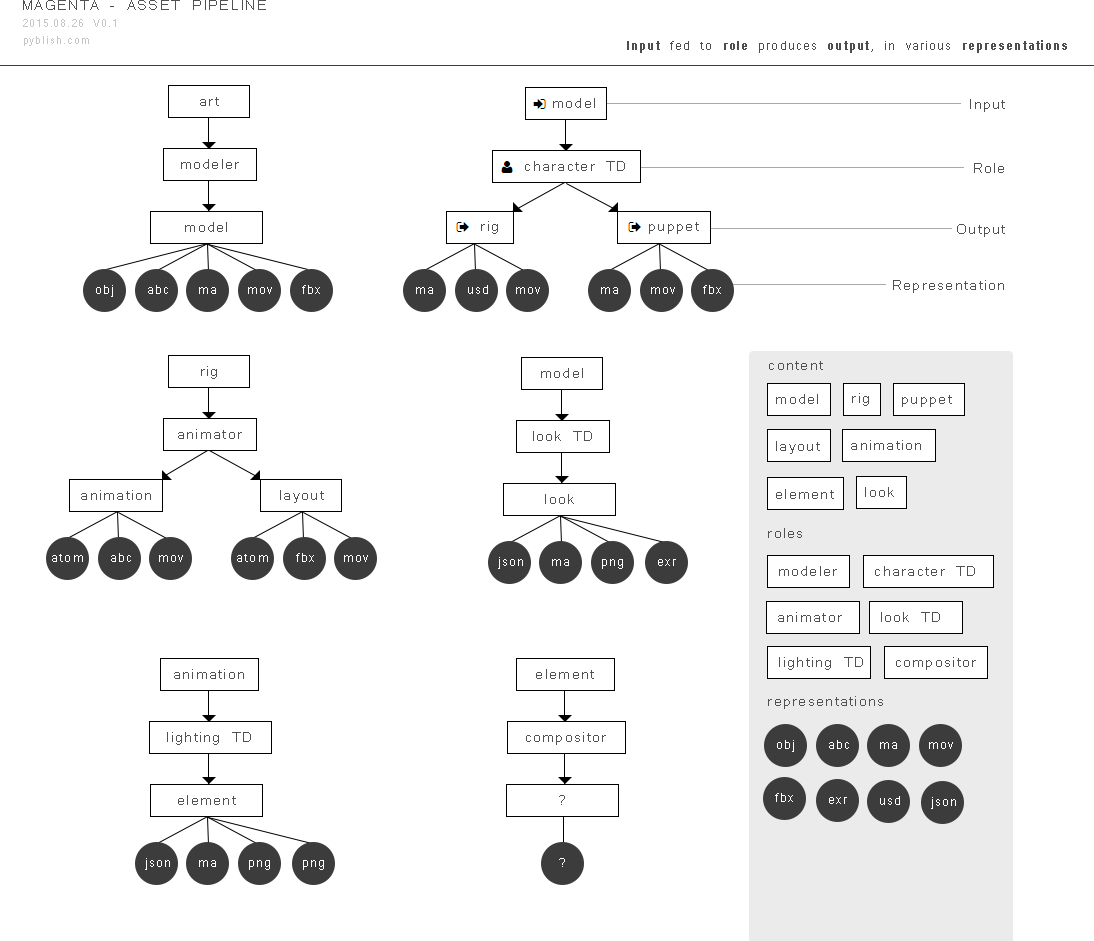
Result
Currently, each family is capable of outputting an arbitrary amount and type of Instance's.
▾ rig
▾ ben
▸ ben.mb
▾ review
▸ turntable.mov
▾ metadata
▸ metadata.json
Which means great flexibility but an awkward directory in between family and file that most often ended up containing a single file.
With the above approach, families contain a single output in various representations.
▾ rig
▸ ben.mb
▸ ben.mov
▸ ben.json
Where the representation is present solely in the suffix of the filename.
This way, the inputs and outputs of artists are the abstract notion of content, such as “animation” and what they actually import and physically make use of is the content’s various representations.
Ok. Looking at the length of this reply it’s to show this is an interesting, but also easily confusing topic.
First, I think you misidentify between content and role oriented. To be more correct with the terms we’re currently working “Task oriented”. That I’m misunderstanding what you’re trying to explain even more shows that this is something that’s confusing and easily misunderstood. This is how I see that terminology make sense:
Content oriented
If the structure wouldn’t be role oriented the outputs would be joined together outside of their tasks. A pure “Content” based structure I think would be (at the very core):
{item}/published/{content}/{version}
So all tasks/roles would produce different content so their content can easily go together. Personally I would never do this.
Task oriented
I think where we want to go is to a place where any Task can have any output. Workflows differ and requirements change over time. I think assumptions will have to made about what Task produces relevant output for another Task (eg. “Model” task creating output relevant for “lookdev”).
Also making this “no assumptions” means it allows re-use of similar plug-ins across multiple tasks. Or even separate for a complex asset into “lowres_model” and “highres_model” task.
XXX oriented
So yes, it seems there’s much here that can confuse someone. To be complete this how if I feel we’re currently doing our structuring:
- Task/Instance/Content/Version
Where Content is family. Yet there might be a lot of different Instances that contain very different data, some might have renders… others might not. Purely looking at the outputs of a folder (eg. looking in `published/) would mean we won’t be able to identify directly if it produced any videos whatsoever, or any models or renders.
Therefore it might make more sense to do it differently, especially from an Artist’s perspective. Someone looking for specific content would likely know less about the instances as he searches for content, but more about what type of content he’s searching.
For example assembling your compositing scene might involve looking for all renders that are available. So you look up the family renders. And you figured you’d need the cached camera as well. You might find it quicker if you’re looking for the family camera that has all instances then when you’re looking for an instance of the camera by name.
Similarly if you’d want to load an alembic into your comp you would search for the cache (or pointcache?) first before anything else.
So this might make more sense:
- Task/Content/Instance/Version
Some examples would be:
ben/modeling/published/model/ben_hires/v01
ben/modeling/published/model/ben_hires/v02
ben/modeling/published/model/ben/v01
The danger here becomes if one instance produces multiple families you get into the same instance being in duplicate places. For example, let’s add some extra outputs:
ben/modeling/published/model/ben_hires/v01
ben/modeling/published/model/ben_hires/v02
ben/modeling/published/model/ben/v01
ben/modeling/published/metadata/ben_hires/v01
ben/modeling/published/review/ben_hires/v01
Yet since we’re decoupling how closely review and model are linked (since they are not of the same version) this also makes me believe it’s more likely those will be different instances anyway:
ben/modeling/published/review/ben_turntable/v01
ben/modeling/published/review/ben_faceTurntable/v01
And whenever something needs to be directly linked, thus having a perfect one-to-one relationship this means they are the same family. Let’s say a model should always specify it’s geometry specs in text-format this would mean you’d extract it within model/ben_hires/v01.
Separating by content
Separating solely based on extension will set you up for failure. Sometimes there’s need to separate content in two similar datatype files (which in majority of cases would be its own instance or even a separate task):
- A rig could be baked differently depending on whether it’s cached for use in a game-engine as opposed to one where it’s used for a render within (for example) Maya, both outputs could still be .ma (or both .fbx)
- Some content could be separated into ‘chunks’ to allow a partial import elsewhere. (This is probably more fit to be a separate ‘instance’ of the output data.
Or they can even have different datatypes with similar extensions
- A gpuCache and Alembic are both .abc files for the same source content but different output structure.
So I think separating the file by name to identify its contents is a big plus (if not a must). This is in line with how we want to have “clearer” filenames to show some what data they hold. We’ve also seen that doing this can create too long names and not doing it has its own unavoidable errors as well; a middleground will likely be taken here.
Just as a note I think this is a clear structure:
{item}/{task}/published/{instance}/{family}/{version}/<files here>
In the case of a model of our character Ben being published in the modeling task this would format to something like:
ben/modeling/published/ben/model/v01/ben_model_v01.ma
Note that I would think a shaderRelations.json is a similar family file as the shader itself. It has a one-to-one relationship with the shader file. They belong together, and as such always extract in one go together.
Similarly AOVs/renderElements belong with a renderLayer. (Here this relationship is even more present because they can be simply rendered into a single multichannel .exr). For example:
sh1000/lighting/published/masterLayer/render/v01/sh1000_masterLayer_v01_####.exr
Nevertheless if it would be rendered as separate .exr files, this would be:
sh1000/lighting/published/masterLayer/render/v01/sh1000_masterLayer_v01_beauty_####.exr
sh1000/lighting/published/masterLayer/render/v01/sh1000_masterLayer_v01_AO_####.exr
sh1000/lighting/published/masterLayer/render/v01/sh1000_masterLayer_v01_diffuse_####.exr
Ok, I can see we’ve got a few different views on things, it’s good we brought this up now and not later.
First off, do we not want a rigger to be able to publish a model, just because he is a rigger and not a modeler?
This is what I want. To make roles go away. To focus instead on what they can contribute as human beings. It sounds like what you mean by “task” is what I mean by role. That a rigging task can’t create a model.
Note, sorry for the long post above. Have a look at the whole thing again, just edited some parts. Will leave it alone for now and address specifics in new posts as it’s a bit big. 
We do want to allow that. Or at least I would want that.
Do I understand correctly and you do want the same?
To clarify. The ‘roles’ (or I would say “Tasks”) are there purely to identify an expected part within an item. For example we have an assumption of what is going on within the modeling of Ben, yet his output could be artibrary. (He could even set up shader-links for exports to “ease” for the lookdev artist how he subdivided a large item into different shader chunks, not necessarily the best of workflows… but he could).
Does that make sense at all?
But this is what I’m saying is bad.
If we build upon the assumption that a modeling task outputs models, then any other task needing to output a model would have to be tailored to also support the output of models. Such as rigging.
How can we make his output arbitrary, if the output has anything to do with him being a modeler, doing a modeling task? What is the gain of even making this consideration?
I’m saying that if a person opens a scene and formats the nodes in Maya in a certain way that aligns with how models look and work, then it is a model, and can be published as a model. Oops, turns out this guy was in fact a lighting TD working on a lighting task, so now he can’t, because the tools assume he should be publishing image sequences. Bummer.
Still think we want the same thing, but you’re mentioning a current issue within the workflow. Specifically the Collection of a rig done in rigging or a model in modeling is currently done on group naming conventions, thus the layout of nodes.
Yet what I would want, and I think you want that too. Is to have it be explicitly within the scene, like based on an objectSet so that same/similar output could be generated from another Task. If so, yes… we want the same.
At the same time that seems to be a different issue than the “layout/structure of the published outputs”. Correct?
This is “expected” to a human, not to a computer. I meant it more as like it makes sense to have an animation task since we can “expect” what is happening in there. Might be saying it poorly here.
Cool, agreed on all points.
The collection could operate on an objectSet, sure. The objectSet could have a user-defined attribute saying it’s a model, like in Napoleon.
Mm, certainly. To artists and scheduling (any social aspect), specifying “animation” as what they are about to do makes sense. I just don’t want tools built around it. Edit: such as the asset library, or instance manager.
Ok, next point, representations via the file suffix.
I should have been more clear, I didn’t actually mean the file extension, but just suffix of any kind. It just so happens every suffix I so poorly chose was an extension, such as .abc, but it could also be _gpu.abc.
To keep separating what is a name and what is a representation, I might go for .gpu.abc instead.
The point is making it obvious that each file of the same name within the same directory are actually the same thing, just represented differently.
Thoughts?
Clarity in naming the set
I think we might also want to show the type of publish in the name, but that might be more a preference than a requirement. Just because it’s easier to spot. I do know Artists find it easier to manage it in the name than in an attribute (especially if string attributes since they show only in Attribute Editor).
For example: ben_model_PUBLISH is very clear about what it does as opposed to ben_PUBLISH. Similarly I think the suffix used for publish is SET or SEL which seems to be very related to it being an objectSet or selection set, whereas we want to distinctively use this set of nodes for publishing. We might want to make that more obvious. Thinking out of context (eg. a new freelancer coming on board) seeing a _PUBLISH node would be more the point and instantly clear than the others.
Could be a nice point to be explicit about the contents. Working with attributes gives us more freedom (for example a checkbox could set its default state whether it should be published), but I think we should recommend a naming convention for the node that is clear on its own.
Representations via file suffix
Sounds perfect!
Could be an option, but I also currently have in mind that @mkolar mentioned having issues in the past with frame numbers and dots. And since we aren’t sure what content we might be dividing we should take those issues in consideration.
In this case it’s very relevant, because this same suffix would be what the different channels are for a render layer. This is similarly different content and the same type of data-structure (file format).
layer.AO.####.exr
Or:
layer_AO_####.exr
If it’s for readability and clarity for humans and computers I think the top one makes most sense. We’ll just have to run through it and ensure there are no issues with major applications.
Instance first or Family first?
The Task/Instance/Content/Version versus Task/Content/Instance/Version is also an interesting discussion. For example a renderLayer instance has almost no meaning outside of its context of the content (note that in terminology for me here content == family). See under XXX Oriented.
For example imagine these instances:
lighting/sh010/characters/renders
lighting/masterLayer/renders
lighting/sh010_cam/camera
lighting/trees/renders
Whereas family first would have been:
lighting/camera/sh010_cam
lighting/renders/characters
lighting/renders/masterLayer
lighting/renders/trees
It also makes more sense for a producer to have a look over the review instances/output like so:
modeling/review/turntable_ben
modeling/review/turntable_benFace
As opposed to:
modeling/turntable_ben/review
modeling/turntable_benFace/review