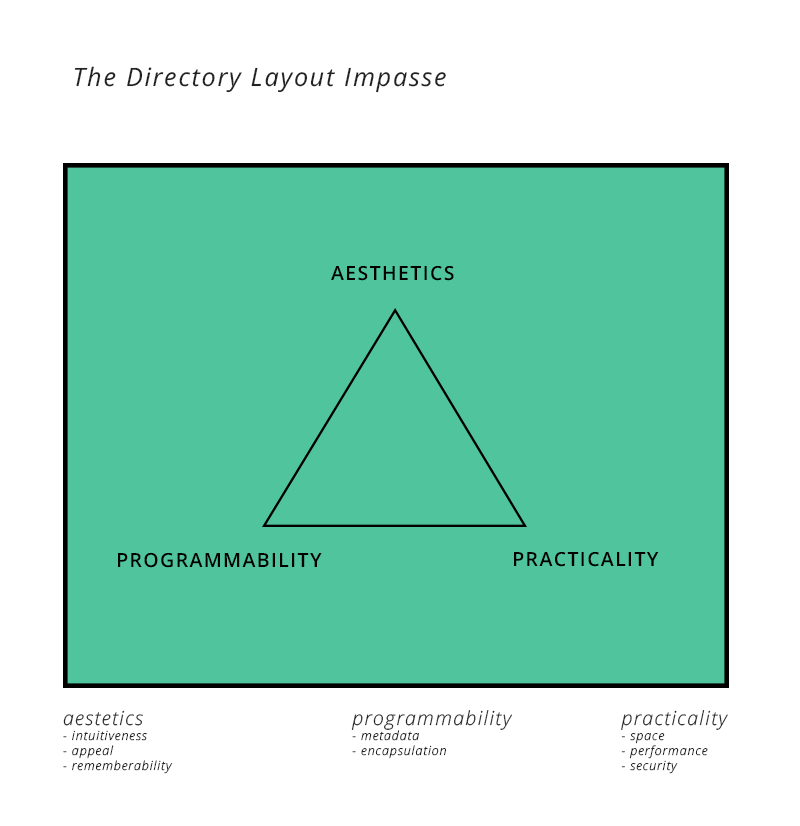
I figure I’d provide a practical example to let it settle in.
Starting a shot
Let’s assume a scenario in which an artist is about to begin working on a shot. He’s been given Task A to work on Shot B from Film C, and he is an Animator.
$ cd /projects/filmc
$ cquery find .Shot
/projects/filmc/shots/ShotA
/projects/filmc/shots/ShotB
/projects/filmc/shots/ShotC
$ cd shots/ShotB
$ maya
From that point, the directory he is in, along with the user he is logged in as, is enough context for a tool to launch an appropriate session of Maya relevant to his task.
Querying parent project
From a tools perspective, let’s assume the tool has been given the path to an asset and is sensitive about displaying information relevant to which project it is in.
$ cd /projects/filmc/shots/ShotC/animation/private/marcus/maya/scenes
$ cquery .Project
/projects/filmc
From that point, data can be extracted from the project, either from metadata local to itself or e.g. FTrack if desired. The critical thing here is that each asset along the way knew what they were and didn’t require an external query.
In fact, neither of these require any interaction with anything other than the content itself. I’ve referred to it as “smart content” and I think it fits.
Where does it go?
In relation to figuring out where a file should go, this is where the parent project Open Metadata comes in.
# Basics
$ om write key --value="value"
$ om read key
value
# Usage
$ cd /project/filmc
$ om read assetsDir
subdir/assets
# More
$ om read shotsDir
shots
$ cd subdir/assets/MyAsset
$ om read developmentDir
private
The critical point here is that, the project itself is in control over where it’s children go, and it’s children are delegated a similar responsibility. This is the “decentralised” part of OM.