Not sure what you mean here. But for me the container is information about the workspace, the actual asset you’re working on. The actual assets’s name being in the directory is also not a necessity. Each shot could be saved with a UUID where the artist never actually sees the underlying folder structure.
Basically the only thing the Selector currently needs outside what be adds is the container information. It’s information about the current asset you’re working on so it would be great if it could be added to the environment data.
It is for building output data, yes. But possibly also retrieving additional data about the current asset. At best I want to have data available that allows me to format paths and have me skipping the need to actually parse any paths. Currently I still have to parse the current folder to retrieve the data that I want.
I guess the question is how would I implement something for be that ensures whenever an asset is entered additional custom data is added. For example if I want to retrieve data from a database upon entering? How could I set it up?
Next to the yaml files in the project we could have a be_get.py or something that contains a class Getter that defines how data is being retrieved. By default that file could do something like from be.api import DefaultGetter? And if someone wants to have a customized Getter they could implement it within that file or import it from there own library?
Would it be possible to use be also purely python based. Something like be.enter('thedeal', 'ben', 'modeling') ?
Before we go any further, could we try keeping our feet on the ground and actually implement a plug-in that illustrates the problem?
A UUID for shots, a database getter for project initialisation and a Python API for be isn’t something we’ve encountered a need for in The Deal yet and I would like to see how and why it fits before struggling with a solution for it.
Try not to think of initialisation and publishing as the same thing. Publishing hasn’t changed, we still need Lucidity to build output paths. be is only for getting into the project environment in the first place, its techniques and solutions are separate, even though they both currently use formatted paths, which is a coincidence at this point.
I’m working on extracting playblasts from assets and have encountered some good issues to discuss.
Extraction and Conform of the model currently happens in the same plug-in, meaning we can’t reuse any of it for extracting playblasts.
Data relevant to figuring out where to write the model is currently written in the model selector, which means we can’t reuse it for the playblast selector.
Most importantly, publishing happens to it’s final destination immediately, which means we will have to re-compute the output path once per output.
These are good reasons to talk about why Conform/Integration is neccessary.
When outputting multiple files that belong to the same asset (i.e. “representations”), the idea is to write them all to a common folder during extraction, a temporary directory. Every extractor writes to this one shared directory, until Conform comes in and moves it into place.
This way, extraction needn’t bother with schemas or final paths, it only has to worry about getting the data out of the host. As an added benefit, a final destination will only ever have to be computed once, in the one conformer.
As another added benefit, it means we can output auxiliary outputs, like playblasts, that aren’t really the asset, but still somehow belong to it. You’ll notice that the review instance is a separate instance, which it must be if it is to have it’s own validators, extractors and such. But being it’s own family means it can’t take part of the output path generation, because that is based on the parent instance, in this case model.
When extraction happens to a shared temporary directory, a final conform swoops everything inside of it up during publishing, including auxiliary outputs, and positions it in the correct path.
This conformer could either be implemented once per family, or once total.
Definitely something worth looking at. I guess the point of positioning it directly was more coming from the fact that our file server is sloooooow! (New server is coming soon). Also the workstations usually don’t have any local storage space for files, so there’s no way to temporary do a local save. For thedeal that’s not a big problem I guess. Still wondering how the Integration could be optimized.
Also do you have an example of an Integrator that can be re-used? How/where does it define where to save (and how to name) each individual file?
I assumed all input data would be selected in Selectors and Extractors (and Integrators) would solely use that data to define their output. Note that in our Selector it doesn’t define the exact output path, yet it defines all data of the asset to know what we’re working with.
So as I understand it now publishing will not ensure a playblast is available alongside the asset. Actually, the playblast is not even related to the model’s family? Do I understand correctly that we’re not trying to always get the playblast as output when we’re done making a model, but only when someone deems it necessary and creates a _CAP camera?
Would love to get started fixing up the mentioned points in the coming days (hopefully I find some time after work this week). With some starter points on how to proceed with regards of implementation I’ll give this a go. So what would you recommend?
Great. Just checking to see what we’re aiming at. Sounds good @marcus. Also noticed some gif files popping up in dropbox, seems to be going allright?
@Mahmoodreza_Aarabi good to see you’re also working on it! Let us know if you’re ready to start publishing and need help to get the first plug-ins working in that area.
This doesn’t make sense. Saving locally first will speed up extraction, and make putting it on your sever a single continuous stream as opposed to many small ones, speeding up network access as well.
Every operating system has a dedicated spot for temporary data, how do you mean?
Python has a module for this, called tempfile from which I typically use mkdtemp.
The local storage drive is relatively small. If bigger caches are to be created (eg. over 4 GB) it’s likely it won’t fit on the local drive. But let’s give it a go. Especially with the files we’re working with now this won’t be a primary issue.
Blocking things out, mainly, but yeah it’s going pretty good! I’ve worked around the ffmpeg requirement by adding the binaries to our project, and exposing them to the PATH via be. So whenever we enter thedeal, ffmpeg will be available.
The problem has been where to put the output. One way of looking at it, is as a converter of the quicktime extracted, and to do the conversion during conform. But that’s no good, because (1) it couples gif output with mov output and (2) it means not being able to funnel moving files to their final destionation in a common conformer.
It could involve a dedicated playblast just for the gif, which makes sense, since it’s more or less extracting a separate video. But that’s not great either because playblasts can take a large amount of time.
So the trouble boils down to when to perform conversions between file formats that have little to do with the host itself, whilst keeping the ability to funnel all output through a single conformer, where versioning amongst other things happen.
Wooot. That’s not normal, and given that Windows itself needs a certain amount of free space available (2xAvailable memory) it sounds like you’ve got bigger issues with space than for publishing.
This way, the only way to get a Gif, is by first extracting a quicktime. Not a big deal, I think. It also means we’re still able to do all of it in a temp directory, and uniformly conform it into place.
I’ve added the ability to add custom per-project environment variables to be in 0.2.1 so you’ll need to update before you can use this plug-in. It’ll add ffmpeg to the PATH.
Maybe we can have the gif Extractor ordered after the mov Extractor and require the mov extractor to run. Then the Integrator would delete the mov file if it was only created for the gif? Hmm, maybe sounds tp complicated for something simple.
Actually seems like you just did something similar!
Yeah, that’s pretty much what’s happening, except nothing gets deleted. In our case, I think it’s healthy to have both, the quicktime has better resolution, detail and pause/play functionality, whereas the gif is useful for the forums where we review the work.
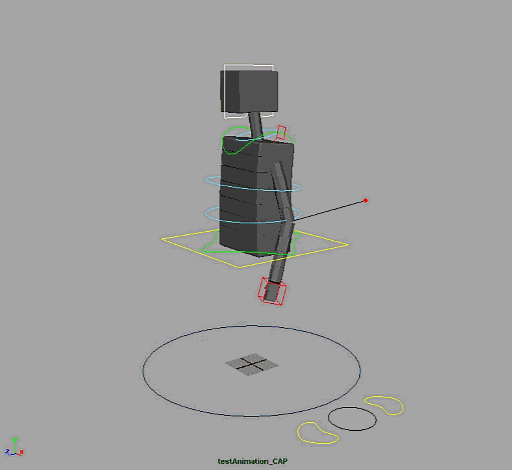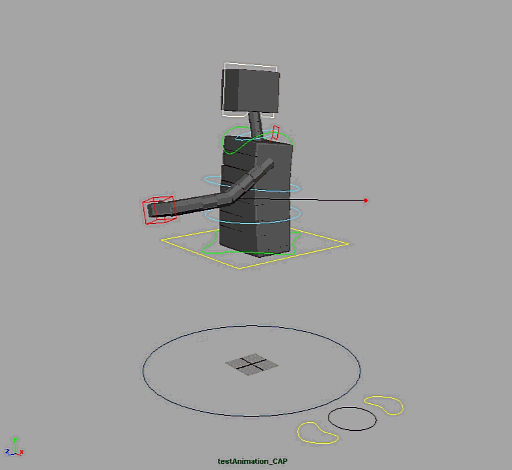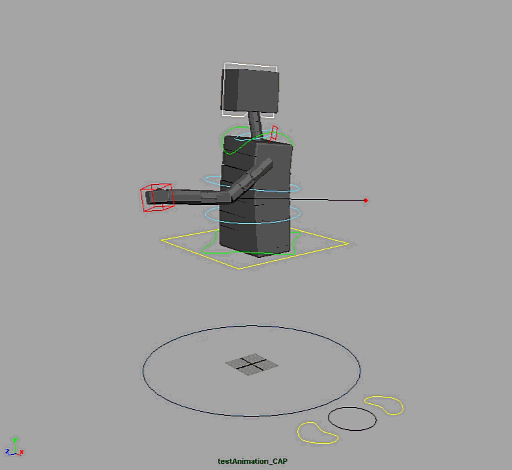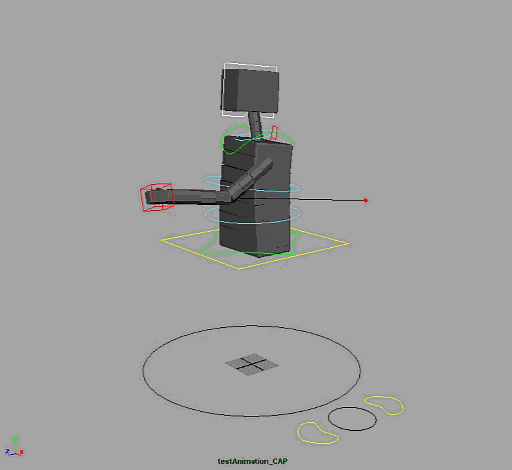
Speaking of which, here’s the model.
I’ve been meaning to talk to you about some of the changes you’ve made. Primarily that he now looks like a robot, like Bender from Futurama. I always pictured his arms to be even thinner, almost like a single stroke, or at the very least opaque and non-shaded, like thick strokes.
What’s your thoughts about the current design of his limbs?
It’s a quick draft and is definitely open for discussion. I’ll have a go soon and see if I can make the next publish work with the Conformer/Extractor separation!
I can relate with mkolar here. 1 particular studio I worked with even refused to use GUI I provided for automatic playblast + compression. Shell/cmd would give them heart attack.
@Mahmoodreza_Aarabi has been busy working on the rig, and it’s looking good so far!
Some things to note, the review extractor won’t work here, because I made up a new asset type for ben called animation that the schema produces an invalid path for, /asset/model///geo\TestAnimation.mov.
Clearly a problem with not first agreeing and designing for a new type of asset, but in a flexible and ever-changing environment, I’m thinking it would be nicer to have it fail more gracefully, such as to a temporary path, or a sandbox area?
@Mahmoodreza_Aarabi
good to see you’re also working on it! Let us know if you’re ready to
start publishing and need help to get the first plug-ins working in that
area.
@Mahmoodreza_Aarabi has been busy working on the rig, and it’s looking good so far!
thanks you bigRoy, yes i’m here and i will rig the character, i hope it will be good, thanks to @marcus too.
i hope the rig be good for animate.
about developing plugins i hope i can, because i am so busy these days.
btw, good luck
What compression would you guys use for Quicktime by the way? Here at work I use libx264 to save out mp4. While the product plays fine in my studio, very often our clients won’t be able to play it, nor my friend’s PC when I try to play the movie from my usb.

 But let’s give it a go. Especially with the files we’re working with now this won’t be a primary issue.
But let’s give it a go. Especially with the files we’re working with now this won’t be a primary issue.
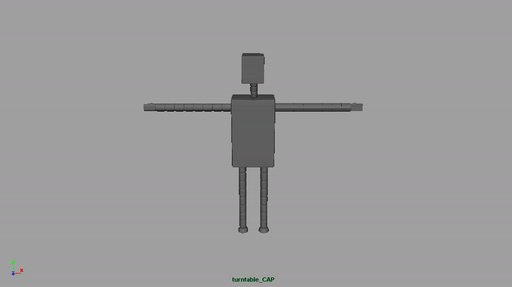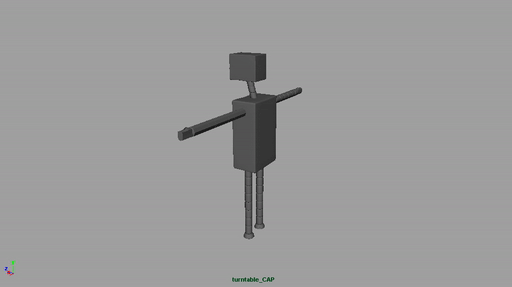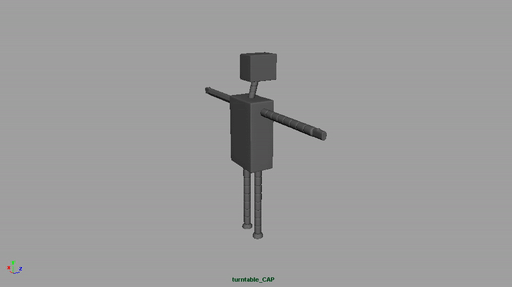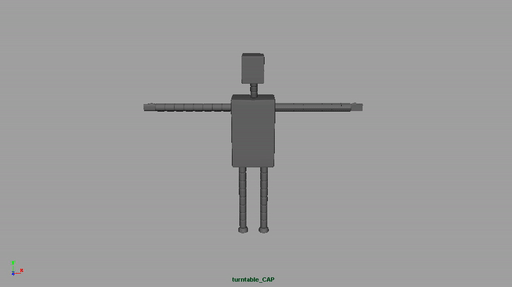
 I always pictured his arms to be even thinner, almost like a single stroke, or at the very least opaque and non-shaded, like thick strokes.
I always pictured his arms to be even thinner, almost like a single stroke, or at the very least opaque and non-shaded, like thick strokes.