Wow awesome Maya 2015 has its own H264 now  More reason to get our animators to use it.
More reason to get our animators to use it.
I’m pretty sure it’s been there since Maya 2013. What version are you guys on?
Our lead animator does not want to move away from Maya 2012.
Ok, I’ve got this going now in my latest commit to my repo. Only ExtractModel has it implemented so far and works together with IntegrateAsset.
Basically the Extractor inherits from pyblish_magenta.plugin.Extractor and uses self.temp_dir(instance) to retrieve a temporary directory for this instance. This directory is stored as data for this instance as extractDir.
Then the Integrator looks for the extractDir data of the instance and moves over the files to its own integrateDir that it computes.
We might still want to discuss about a sandbox directory if the integrateDir cannot be computed. Where would we position the sandbox directory? Close to the root of the project? Or close to the work file?
The issue I’m having with this is that the Extractor is still defining the file names (not necessarily locations). I feel it’s the Integrator that should be responsible for the correct naming of the files, right? Also, I think it’s time to settle on a consistent naming for the integrated files. Let’s start a discussion, what do we want? Especially how do we ensure two extractors don’t create files with the same names (if they stay responsible for the naming of the file)
I’m wondering how to set up the versioning for the Integrator. I was thinking something like this:
import re
import os
# Assume this data is available from the instance.data(), for example:
# integrate_dir = instance.data('integrateDir')
# increment_version = instance.data('incrementVersion', False)
integrate_dir = 'E:/Dropbox/pyblish/thedeal/asset/model/characters/ben/geo'
increment_version = False
# Get the version directories in the integration folder
directories = next(os.walk(integrate_dir))[1]
# Get the versions already available and find the highest version number
found_version = False
highest_version = 0
for dir in directories:
match = re.search('^v([0-9]+)$', dir)
if match:
found_version = True
version = int(match.group(1))
if version > highest_version:
highest_version = version
# Define the current version
current_version = 1
if found_version:
current_version = highest_version
if increment_version:
current_version += 1
# Integration direction with version:
integrate_dir = os.path.join(integrate_dir, 'v{0:03d}'.format(current_version))
print integrate_dir
Here’s Ben with thinner limbs.
Could you make this a pull-request?
Sounds like the Napoleon method of doing things, and should work fine here.
Yes, the sandbox would be useful in two cases.
- The integrator can’t figure out where to put the files; maybe the schema can’t be generated based on the current environment.
- One of the extractors fails for whatever reasons, and we would rather only publish complete sets of content.
In either case, the extracted content could be put into a temporary spot where it can later be integrated without needing an additional extraction. For example, extracting a cache can take a number of minutes and it would be a shame for the relatively quick process of moving/renaming files to fail afterwards.
The way I’m doing it with Napoleon is to have it close to the workfile, relative to it. In the same directory in fact.
├── scenes
│ └── published
│ └── 2015-06-29.0747
│ ├── ben.mov
│ └── ben.abc
├── ben_model_v001.ma
└── ben_model_v002.ma
In the case of Napoleon, these temporary directories are persistent and represents all publishes made from a particular asset/user combination. The idea is to have an external process then crawl the hierarchy looking for publishes older than a certain date and remove those automatically. For example, after a day, week or after project completion.
That’s a good point, yes, I’d also expect the integrator to be the only plug-in to know about the naming convention of files. In this case, I would consider the directory of instances as just a placeholder and not actually move that along during integration. Instead, take each file independently, name it appropriately and copy/move it into the target location.
I would copy, always copy, until a publish is finished and double-checked for consistency. Otherwise we might end up with one of the file writes throwing an exception mid-way, which will become difficult to redo. Once done, the original can safely be removed.
I’m wondering how to set up the versioning for the Integrator. I was thinking something like this:
Yeah, that’s about the gist of how I’d do it too.
I’d be interested to hear how the ftrack guys are handling this. It’s my impression that they ask ftrack for a version number and use that. @mkolar, @tokejepsen, any word on this?
I like it, you?
Hello guys
I want to say that the rig is completed and first final version is on ..\pyblish\thedeal\dev\rigging\characters\ben\maya\rig_madoodia_11_final_01_06292015.ma.
i think it is an appropriate version that we start rigging Validators on it.
beside that my friend @masoud join us for working on animate the work.
Good Luck
1 Like
Great work @Mahmoodreza_Aarabi
Here are some validators that come to mind for the current version, rig_madoodia_11_final_01_06292015.ma
- Visibility, a rig should only show what is usable by the animator
- Default values, a rig should always have the same values for every publish. In this case, Maya has the concept of “default” values, e.g.
cmds.addAttr("settings_states_ANM.l_arm_state", dv=True, q=True)which should always correspond to the current value during export
Now @Mahmoodreza_Aarabi, don’t fix these. We’ll need these problems to create the validators. Once the validators find them, we can start to fix them and make sure that validation passes when we expect it to.
If you want you can create these validators. @BigRoy, what do you think of these validators, and do you have anything similar at the moment?
Current approach is, firstly getting the file version from the name of the current file and saving it into context at the beginning of the publish. Then we just operate with it in the plugins. We are comparing with ftrack stored versions, but only to make sure we’re not about to overwrite anything or to get existing version in case we’re adding component to it.
The main thing is having the version in the context. everything that get’s published then get’s that version appended to it. (outside of ftrack, I’m also automatically versioning up current workfile, so when artist comes back to it next time, he already has a version created that he should work on.)
Thanks @marcus
Visibility, a rig should only show what is usable by the animator
Visibility of all part of a character will be added with some attribute to hide and show with animator.
but i know, not needed nodes should be invisible
for now i didn’t lock anything in rig, for getting errors.
Default values
i try to work on some plugins
i’m not good at it yet, i should learn more about plugin creation.
Do you mean that the content you are currently developing will already have the version it will get once published? That sounds backwards, how can that work?
Shouldn’t the version be unknown until the time of publish? This way, it sound like an asset becomes hard-coded to only be publishable by a single artist.
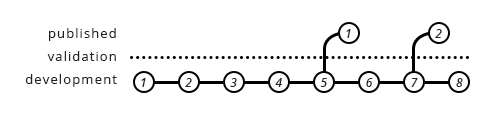
Taken from here.
We work on quite different premise.
Working files look like this.
Working Files Published Files
filename_v01_01_comment.ma
filename_v01_02_comment.ma
filename_v01_03_comment.ma ---> filename_v01.ma
filename_v02_01_comment.ma
filename_v02_02_comment.ma ---> filename_v02.ma
filename_v03_01_comment.ma
we might have 20 revisions of v02. They would be numberd and comment could be anything. stage of work, name of the artist (it’s up to people to use it or not). Most of the time we don’t care who worked on the file. It’s irrelevant piece of information for us, unless the file has been taken offsite, then it’s compulsory to append their name to comment to prevent potential filename clash, if someone worked on the same task in-house (didn’t happen thus far.)
This way we can trace back what work has been done to get from v01 to v02 if needed. In the system you posted, we’d have to store information about which dev version produced which publish version if we wanted to be able to trace it back.
For some smaller shows we’ll be moving to a bit more open dev files naming, but one thing will remain rigid and that is v## string in the filename stating which version would be published from this file if it get’s published.
As for the situation when 2 artist are working on the same task and one publishes v02, but other is still working on v01. Well then someone screwed up royally (coordinator? supervisor? artist?). The point is we never ever do that.
1 Like
I’ve seen this format before filename_v01_01_comment.ma, but then as filename_v01_r01_comment.ma where the v stands for the version to be published and the r stands for the revision of that version.
I actually considered that before, but then decided to just use number, because technically, we could put whatever in there to differentiate the files. Even if artist is super sloppy and uses name_v01_iForgotToPutNumberThere_soIllPutItHere-01a.ma, we’ll still be ok and the file is clearly differentiated from the others, It up to the artist then of course to know the mess he’s making in workfiles, but as far as something get’s published out of it. I don’t give a damn.
1 Like
You misunderstand, I’m talking about when an asset is published by more than one artist.
For example, a first verison of the hero character is published by Daniotello. Later, an update is made by Ricotelle who produces a second version.
What happens for you here?
I get file_v01.ma from Daniotello (I don’t care who from) and file_v02.ma from Ricotelle (again, don’t care). They are working from the same work folder. We don’t use personal folders, but ‘task’ folders instead. I want people to be aware of what’s going on with the task. This way if rogue files start popping up in the folder of my task. I stand up and shout, ‘who the hell is working on the same thing?’ or just look at the file author and go have a chat.
1 Like
Sorry if I seemed to question your judgement, that wasn’t the goal. We can move on.
hahaha, that didn’t even cross my mind. Even if you did, good for me, I might find that we’re doing something wrong and change it. I’m not very touchy, just tend to fly stronger words here and there ;).
@BigRoy, looking at the new integrator in the pull request, I have some comments.
class Integrator(pyblish.api.Integrator):
def compute_integrate_dir(self, instance):
# Get instance data
data = {'root': instance.data('root'),
'container': instance.data('container'),
'asset': instance.data('asset')}
family_id = instance.data('familyId')
if not family_id:
raise pyblish.api.ConformError("No family id found on instance. Can't resolve asset path.")
# Get asset directory
schema = pyblish_magenta.schema.load()
output_template = "{0}.asset".format(family_id)
dir_path = schema.get(output_template).format(data)
return dir_path
def integrate(self, instance):
extract_dir = instance.data('extractDir')
if not extract_dir:
raise pyblish.api.ConformError("Cannot integrate if no `commitDir`"
" temporary directory found.")
integrate_dir = self.compute_integrate_dir(instance)
self.log.info("Integrating extracted files for '{0}'..".format(instance))
if os.path.isdir(integrate_dir):
self.log.info("Existing directory found, merging..")
for fname in os.listdir(extract_dir):
abspath = os.path.join(extract_dir, fname)
commit_path = os.path.join(integrate_dir, fname)
shutil.copy(abspath, commit_path)
else:
self.log.info("No existing directory found, creating..")
shutil.copytree(extract_dir, integrate_dir)
# Persist path of commit within instance
instance.set_data('integrateDir', value=integrate_dir)
self.log.info("Integrated to directory '{0}'".format(integrate_dir))
return integrate_dir
I can see why you would abstract this portion as much as you did, but I think it’s a bit too far.
There is now a contract established by the base-classes coming from Pyblish Magenta, which will make it more difficult to anyone to get a sense of what a plug-in does without first looking deeper into the utility libraries.
integrate_asset.py
import pyblish_magenta.plugin
class IntegrateAsset(pyblish_magenta.plugin.Integrator):
def process(self, instance):
integrate_dir = self.integrate(instance)
I would instead suggest establishing this contract between the plug-ins, that a certain set of extractors provide a certain set of information for a certain set of integrators, in this case only one.
That way, we can point to for which plug-ins the contract applies and know for certain that no other plug-in make use of it. Keeping each plug-in as minimal and self-contained as possible.
I think utility functions and classes are ok if they are obvious in what they do. For example, the temp_dir function of your Extractor superclass. The reader of a plug-in doesn’t need to know exactly how it does what it does to know how a plug-in works, only that it provides a temporary directory.
Let’s shuffle it around to simplify it for everyone jumping into it. No problem!
Does that mean each Extractor get its corresponding Integrator? Or what are you proposing?
It means that a series of extractors are associated with an integrator. They form an agreement on what data to provide, and what data to expect. In this case, any extractor that deals with an publishing parts of an “asset” - e.g. the model, rig and turntable - is providing data for an integrator also dealing with assets, in this case integrate_asset.py.
1 Like