GOAL
suggestion of a new feature i’m planning.
the goal is to be able to
- costumise your pipeline, by choosing which plugins to use or not use.
- overwrite settings for plugins, assign actions, etc.
this will be helpfull once the package manager is out, and we can use shared plugins.
in this case the target for your plugin might be different than the target from the build in plugin.
a lot of settings or passed through context or env vars, but in a way that they only will work with similar plugins.
this pipeline config would allow all these different plugins to work together more smoothly. and give you an easy overview
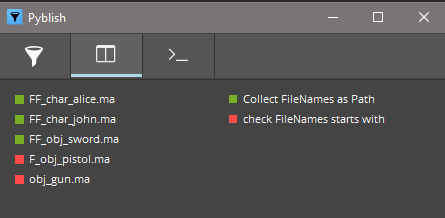
current tech in pyblish
pyblish already has targets and filtering
but targets are set per plugin, and filtering requires you to script quite a bit if you want to adjust plugins.
it’s pretty good at adding and removing plugins, but overwriting settings requires you too know exactly what you are doing.
and having an overview of your pipeline is hard if it’s done in code
so i suggest to add some kind of
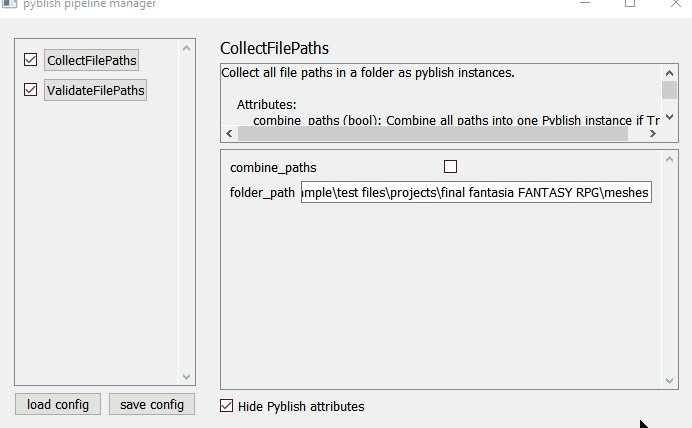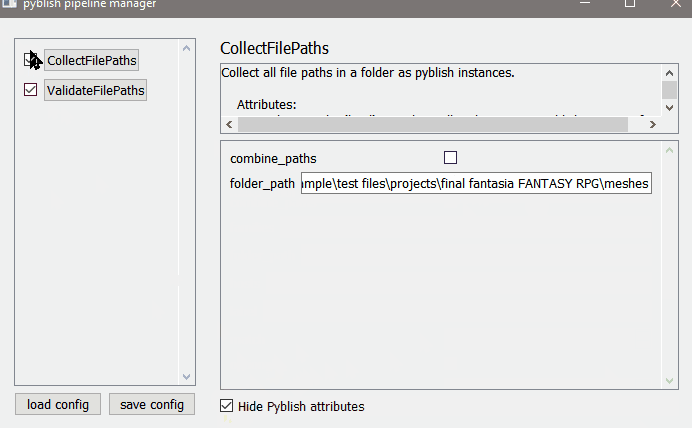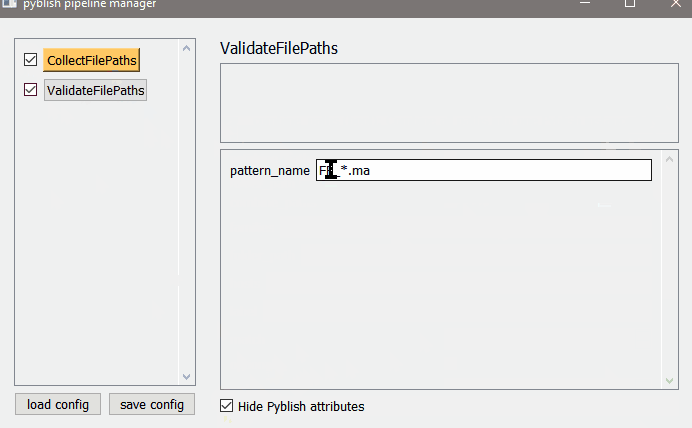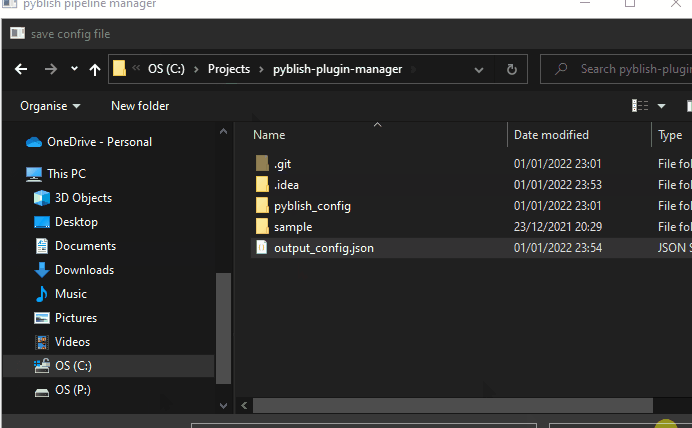
1. pipeline manifest. ( aka project manifest / workflow config / pipeline config /…)
a config file that you can register before discovery.
it would piggy back on the current filtering mechanic for now.
2. manifest creator/editor
register all plugins
open the manifest editor to overwrite default plugin settings
hit bake/save/export to create a config file with your settings in
this could tie in with the package manager eventually
since this, just like filtering, clashes a bit with the data driven approach.
should this be a separate repo? (the UI for the manager/creator likely will be)
what about the config loading?
i imagine it to work something like:
from pyblish import api
api.register_plugin_path('C:/shared plugins')
api.register_config('C:/project/workflow1.json')
plugins = api.discover()
register_config would then read the config, and register a filter based on it.
any properties found in the config would be overwritten in the plugin.
it would also support hooking up new actions to plugins.
config example :
plugin_name
action = [action_name]
__name__ = “spiderman exporter”
meshname = “spiderman”
additive_property += 3
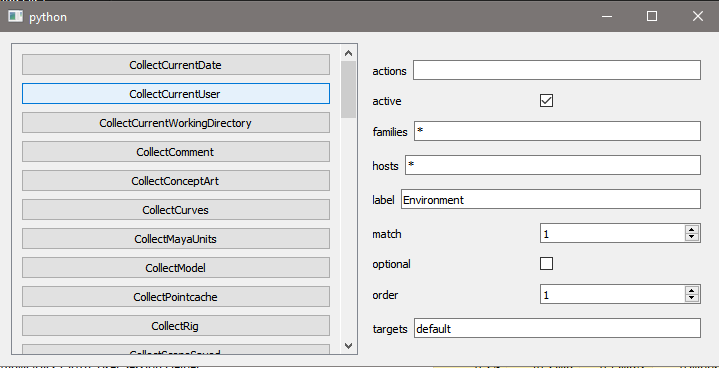
 apply config to registered plugins
apply config to registered plugins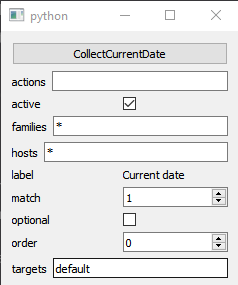
 This was key for me, and something I didn’t see in the original post. It’s important we compare and contrast existing methods of achieving a particular goal. If both approaches are to exist in parallel, they need to be clearly distinguished and have a solid reason for existing.
This was key for me, and something I didn’t see in the original post. It’s important we compare and contrast existing methods of achieving a particular goal. If both approaches are to exist in parallel, they need to be clearly distinguished and have a solid reason for existing. )
)