Great writeup, I think these kinds of proposals are what can push Pyblish and publishing in general forward.
That said, this particular approach is backwards. Or Pyblish is backwards. It’s one or the other. And I see this idea every so often, both in bespoke pipelines and commercial ones. I think Shotgun works this way, where you define a processing pipeline upfront, and then summon each step in that pipeline explicitly.
But Pyblish works the other way around. It’s so-called “data-driven”. Meaning that the processing pipeline is defined by the content you push through. For example, if you publish a model, the modeling plug-ins are called. If you publish an animation, the animation plug-ins are called.
This concept carries through with each level of granularity.
Publish a character model, plug-ins related to models and characters
Publish a character model, in a particular project, at a particular location, and plug-ins for that specificity gets called
The way you control this pipeline as an artist, is by authoring your content to fit the pipeline.
What does a character model look like? It’s a series of meshes in a group with a _charModel suffix
What does a rig look like? It’s a group with a _rig suffix
What does an animation look like? It’s got an objectSet called animOut and an optional namespace
And so forth
Who defines these _charModel and _rig suffixes? You do, via the collectors. The job of the collectors is to venture out and scan for what the user has created, and associated the appropriate plug-ins to their content. if they’ve got both a model and a rig in their scene, they could both be picked up, independently, and associated with their relevant plug-ins. It wouldn’t matter.
And what if suffixes aren’t enough context for an artist to provide? What if they needed to include whether they wanted their animations published as both ATOM curves and an Alembic cache? Well then the collector could also look at attributes on this group, such as exportAtom = true and exportAlembic = true, whereby the artist can either create these attributes themselves (painful) or have an authoring tool to prepare their work for publishing.
Here’s an example of such a workflow, which was the starting point for Avalon which carries this idea forward.
With this in mind, in order to give artists - both tech and non-tech - control over the pipeline, the solution may not be giving them control over which plug-ins to run; but the means to help your collectors recognise what it is they want to publish.
my current project setup w pyblish is data driven, just like you say
Publish a character model, plug-ins related to models and characters
yet i still feel the need for this config setup.
i’ve read the discussion in https://github.com/pyblish/pyblish-base/issues/343 when filtering was added, and various docs where you explain the data driven approach. so i see where you come from.
but i feel limited in pyblish in some areas, tell me if i missed something:
authoring your content to fit the pipeline … Well then the collector could also look at attributes on this group …
this mean maya scene need to be editted, attributes in a group, suffixes in name, …
it also requires a helper tool.
I want to run plugins on any scene without changing them.
I want to change plugin settings without changing plugin code (w inheritance) (this is to work towards reuse plugins across studios, projects, …)
i only want to write custom collectors when needed, and reuse everything else.
workflow management.
if my collectors always run, in a scene with both rig and animation. both rig and animation get collected. what happens when i click publish, if for example i only want to publish the rig?
pyblish would publish both.
Currently i register different plugins for different workflows to handle this with a helper tool. this is the same as target in a way, the issue is that target is set in your plugin so needs changing per plugin, again plugin settings.
or have an authoring tool to prepare their work for publishing.
i envision this pipeline manifest acts as said authering tool, to work together with pyblish.
the MVP is getting close to finished so it will be interesting for the discussion to set up some examples in maya and test out the areas i believe current Pyblish struggles with.
Great. This was key for me, and something I didn’t see in the original post. It’s important we compare and contrast existing methods of achieving a particular goal. If both approaches are to exist in parallel, they need to be clearly distinguished and have a solid reason for existing.
I’ve also re-read my own comments on the link you posted to issue 343, and I realise I sound like a broken record. I also realise I appear to be in a minority, since everyone else opposes the data-driven approach. So just in case there is a silent majority out there, now is the time to make yourself heard, because if this proposal makes it through, it may affect you.
If it so happens that the reverse workflow is better suited to those using it, then it only make sense to go that route. Even if I personally aren’t in favour of it. An opinion I’m open to change given enough evidence of the benefit.
So, let’s dive in!
I struggle to think of a usecase here. Most of my career has been on the artist-side of this equation, and when I publish something I’m the author of it. I created the whole thing, I change things all the time. Changing things is what I do. So changing things in order to align with a publishing pipeline seems like an obvious thing to do. What am I missing? What is the usecase? Who’s publishing that cannot also make changes?
Not true, it would give you the option of publising both. But a collector could both pick up on a disabled state of your rig, or the user could at run-time untick the rig instance ahead of publishing.
Not to mention it would be exceedingly rare for it to happen, so rare that it must be intentional. A solid collector would be able to differentiate between a rig being published, and a rig having been referenced for animation.
Yes, good idea. We can solve the problem from both ends, and compare and contrast the result.
i am not sure if it would make sense to merge this suggestion directly in pyblish , for now i’ll keep it a separate repo to see how it goes. Maybe pyblish will be served in 2 flavours, data driven or predefined. and the user chooses based on their needs.
dirty scenes
in the ideal world all scenes are setup from the start according nice rules, in a predictable way, and pyblish runs to ensure this.
but often i work with existing scenes, most very messy. and lots of them.
if i want to use pyblish to fix this, but can’t use pyblish straight out of the box, without first doing some cleanup, the entry barrier to using pyblish is higher. making it more likely to not be used.
adoption for new tools being used by the user (artists or TAs usually) already is difficult. if we add a requirement that said tool will only work if your scene is setup in a certain way, they likely wont bother to try it.
if the user, let’s say an environment artist, only ever works with environment art pieces. There is no point to run any other collectors. It shouldn’t matter. but what if the colelctors pick up an isntance by mistake. there is a bug, or a edge case. the pipeline has more points of failure now.
a second issue that we can run in is, if my collector picks up meshes based on say suffixes, and there is a typo in the suffix the mesh wont be picked up. this makes complete sense, but is unintuitive to the user. what they sometimes want is to force the environment checks on said mesh. select their own input for the collector.
i find the data driven approach is great when all your scenes are set up in a good consistant way, and pyblish is there to enforce it stays like this. but if you get dropped in a project with no consistant naming conventions, file structure etc, pyblish struggles currently. and this is where it might make sense to go to a more predefine workflow.
mesh authoring tool
making dirty scenes clean sounds like a mesh authoring tool
you pointed out somewhere on the forum before. pyblish is not a mesh authoring tool. but this is where it shines IMO. the validation part of pyblish is perfect for this. and some pipelineTDs i talked with agree that’s their favorite feature of publish.
medic is the only other maya validation tool i found so far, but a lot less polished compared to pyblish. It has similar features but more aimed towards mesh authoring, validating and fixing.
Pyblish is a more complete package IMO, with support for multiple dcc, and forms a better base to work on. Since there is no existing authoring tool that i know off that fills my needs, i’m planning to make it on top of the framework of pyblish. now this does not has to become part of pyblish, but i feel there is a need for this kind of tool.
Yes, the user can uncheck the extractor, but it’s not that intuative.
much more understandable for the artist to know they are running the animation exporter, and will never accidentally export a rig.
you correctly point out that with good collectors this should not happen.
plugin settings
all this talk about preselected plugins vs data driven plugin discovery.
but another point this config approach touches is settings overwritten from outside the plugin.
is there any more input from you on this?
this would enable sharing plugins, reusing plugins per project, studio, …
example: a collector that collects meshes with prefix, read from the property “prefix”
prefix = “CS_” for counterstrike
and could be set to collect meshes with prefix “BF_” for battlefield
currently this is already possible in pyblish, let’s say you set a env var and read from that, or the collector reads from a config file.
but it feels cleaner to read from an attribute of the plugin. easier to make it consistant between shared plugins.
pyblish discovery filter could also do this, but not in a straight forward way.
this pipeline config actually piggybacks on the filter system for now, and is just an easier way of controlling your filters. the main point i try solve here is accessibility for changing plugin settings and controlling plugins. ( i believe discovery filters are not even documented yet, the only info i found was in the source code and issue 343)
Hey Hannes, we use a hybrid approach and it seems to work for us (so far). We essentially wrote a bootstrapper for Pyblish plugins, and it loads the tests we want (I personally prefer the explicit approach). We resorted to a JSON file where you specify families or explicit plugin paths and each of our publishing tools calls the bootstrapper with its own JSON file. Took less than a day to write and test. We didn’t want to add additional metadata to our scenes (there’s already far too much to manage). Keep in mind our publishing tools are separate/custom; we use Pyblish exclusively for collecting/testing.
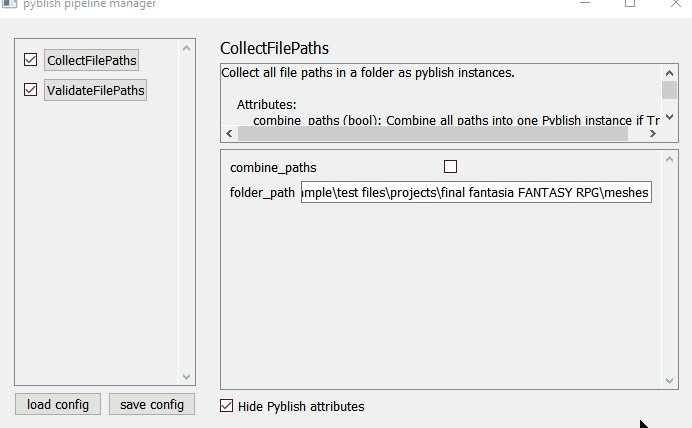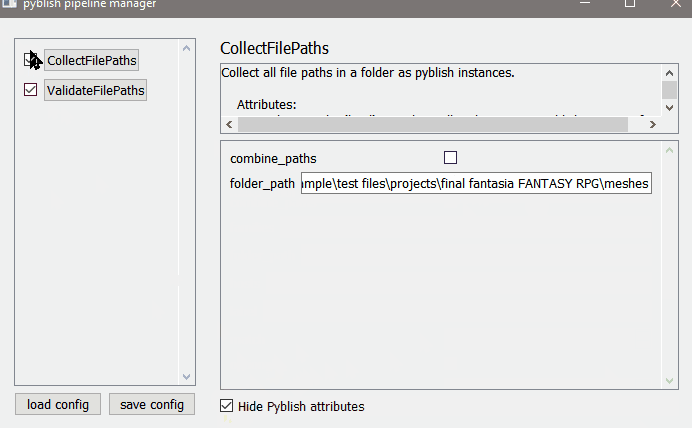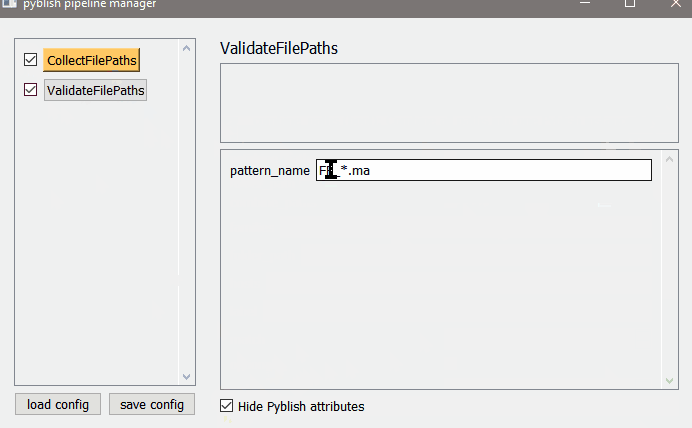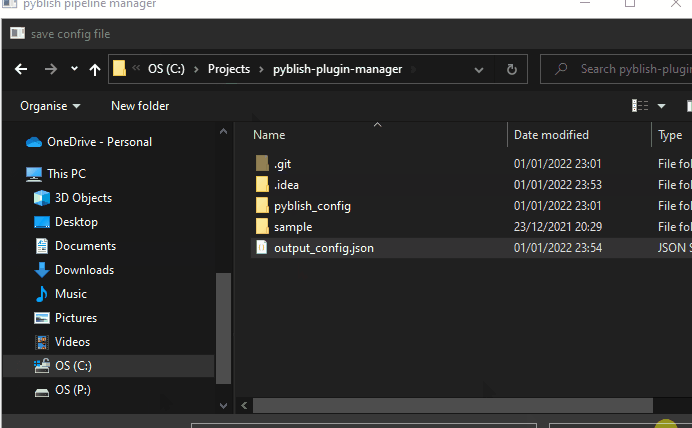
i used the holidays to work on the pyblish plugin manager, and finished the MVP.
using it is simple:
1. create a pipeline config
create a json file: {[plugin_name]:plugin_settings, …}
or you can use the GUI tool i made for this.
2. apply a pipeline config
register plugins like normal, then register the config. (which is a pyblish plugin filter)
from pyblish_config.config import register_config_filter
register_config_filter('sample_config_folder.json')
import pyblish_lite
pyblish_lite.show()
your plugin settings are now applied, explitely.
the implementation uses pyblish filters, and compliments all current pyblish features.
no re-architecturing is needed
most time was spent on making the config creator intuitive/ userfriendly.
the code currently lives outside of pyblish base repo. we could bring the load config function into pyblish base. (a single function)
all other code is related to the config creator which like any pyblish UI has it’s own repo.
there likely will be overlap between the config creator, and the plugin manager (think plugin marketplace, where you read descriptions of public plugins)
for now i want to focus solely on explicit plugin management, so pretend the marketplace doesnt exist yet.
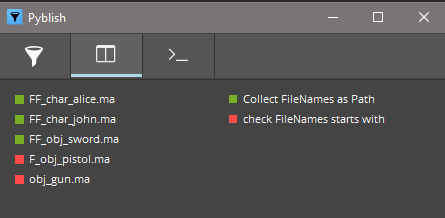
hello, i run an imaginary studio working on 2 game projects:
BF (battling field)
FF (final fantasia)
My team made a lot of plugins (2 !!) for the first project, FF:
a collector. collects files in a (hardcoded) path
a validator, ensure files start with the project’s prefix, FF (hardcoded)
Now that I started on my new game, BF. My studio would like to save time and reuse the plugins from the previous project, FF.
But it takes so much time to recode said plugins. (just pretend … )
when we run the plugins, we collect and validate files:
options A:
recode all plugins, maybe make it load from a config file, or inherit the plugin and overwrite the attribute in the child class
option B:
overwrite plugin settings externally without changing plugin code, using the new pyblish filters feature
advantage: the same plugins can be shared between studios, or projects. and we just change settings.
I’ll play the opposing side and ask the difficult questions to hopefully solidify this concept.
What makes the plug-ins for FF specific to FF? Could they be made more general?
If they are so specific to FF, can they even be shared with BF without a rewrite?
If they can indeed be shared, then could FF simply not add the path of plug-ins from BF to itself directly?
For example, an FF plug-in might look like this.
class ValidateNames(...):
def process(...):
assert name.startswith("ff_"), "This wasn't an FF name"
Which would make sense to keep limited to FF, maybe even given a FF-based family, such as FF_validateNames. But this could not be shared with BF, since BF would like have a different naming scheme.
On the other hand…
class ValidateNames(...):
families = ["anyAsset"]
def process(...):
assert name.startswith("ast_"), "This isn't an asset"
This would already belong in a global repository of plug-ins and could be applied to any and all projects already, not needing any explicit sharing or config files.
Follow up questions.
Is this a scenario you are looking to solve?
What does your proposed solution do differently/better/worse?
Re-watching your GIF, which is very long and hard to follow. An mp4 would work better here, so one can pause, rewind and get a sense of where in the video you are chronologically.
You seem to tackle this issue with what I gather is the unique selling point; that the name isn’t actually in the plug-in but in this separate config file? If so, that’s a good idea!
Looking back at the original problem, I’d imagine we can re-reflect with this new (to me) information in mind.
The config file proposal also uses/requires a helper tool
For these final three, could they be solved by having plug-ins reach out to a config file explicitly?
class ValidateName(...):
def process(...):
with open("c:\path\to\config.json") as f:
config = json.load(f)
assert name.startswith(config["nameSuffix"])
Where the path to your config could be coming from an environment variable e.g. CURRENT_CONFIG=c:\path\to\config.
If a studio already has a database, like Mongo, the config could even be an address, e.g. CURRENT_CONFIG=mongo://this/config whereby the interface to edit it is whatever interface you already use to manipulate a databaseli, like the Shotgun UI.
The advantage being that it’s natively Pyblish with no extras, and made explicit within the plug-in itself.
1. set plugin settings externally from a config (avoid changing plugins / code)
it makes reusing plugins easy.
the aim is download plugins from somewhere, and set their settings externally.
plugin authors can expose settings as public variables
the plugin itself can be a black box.
limitations:
only works if the plugin exposes settings in a public variable
it does not work with your hardcoded example assert name.startswith("ff_")
making settings a public variable of a class is pythonic, and therefor a realistic expectation of the plugin author. Pyblish docs should encourage this.
2. explicitly register plugins for certain workflows
several people asked this on the forums, or created their own solutions, bootstrappers etc.
(myself included) highlighting the need for explicit plugin registration.
a example from my own experience:
i want to run a certain collector on several scenes,
but there is no garantuee the scenes are clean and do not contain any other data that other collectors might pick up!
the data driven approach would be clean up your scenes!
the explicit approach allows you to continue without doing so, a necessary evil when working with thousands of scenes made by others without any validation tools.
retro fit pyblish on an existing project (explicit), vs available from the start of the project (data driven)
Ok, I see what you mean. So instead of the data being explicitly created and accessed, it can rely on data being created and accessed like family and label and other class variables already are being created.
And then this tool would load the plug-in, overwrite those values…
In this way, it could be made explicit what is meant for outside access, and each member can carry additional information suitable for authoring/editing via a UI.
options = [
api.String("patternName", label="File Prefix", help="A regular expression"),
api.Number("padding", min=1, max=3, help="Number of zeroes to pad a name with"),
api.Boolean("mustExist", default=False, help="Whether or not a file may not exist"),
...
]
A UI such as the one you’ve built could then generate suitable widgets with tooltips and what not to aid in the manipulation of it. I’ve built something like a few times in the past and it’s worked pretty great so far, such as for cmdx.
great suggestion! and ironic that my current UI is data-driven, and your suggested UI is explicit
the current UI has implicit tooltips, it get’s them from the plugin’s docstring.
it has implicit type for the attribute settings, based on the current value, which atm bugs when the value is None. or 1(int) but also supports 1.1(double)
ex. pattern_name = 'FF_*.ma' , type is string.
your suggestion seems more robust
explicit tooltips.
explicit type
the disadvantage, slightly more work for the plugin author.
instead of making a variable public, they need to read the pyblish docs and understand how options work.
questions
how do we set options for plugins that do not have custom options? ex. default pyblish options such as active, family, …
Can I assume we have those default widgets stored in the pyblish plugin baseclass?
how would these options work with command line access?
ideally we want something like this,
an option named pattername is detected, a matching variable of the plugin is found, use tooltip and type in the UI widget.
when accessing through commandline we can simply do self.patterName = "Something_else*.ma"
example when you want to change default plugin options:
One plugin runs on the meshes family , another plugin runs on the models family.
Both plugins are written in Pymel and would be compatible if they had the same family.
We can externally change families to meshes on both plugins, they are now compatible.
The problem I have with overwriting class members is that it’s not clear which is meant to be overridden and what is not, along with there not being enough information to implicitly derive metadata from just a single value. For example, should that string be a regex, can it contain unicode, and especially numbers which often have min and max limits.
It also opens up for the user using a variable name that Pyblish already uses, like families. Or vice versa, when Pyblish expands its use of variables, suddenly breaking plug-ins that worked before. And it’s the worst kind of breakage, since there’s no way for a user to know what variables may eventually be used. Rez had/has this problem, where user and internal variables share the same scope. It works on day 1, but is a guaranteed problem in the future.
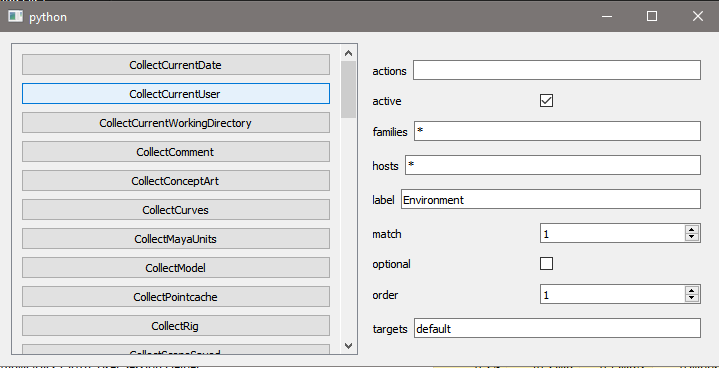
 apply config to registered plugins
apply config to registered plugins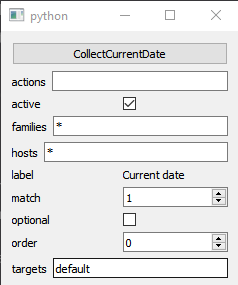
 This was key for me, and something I didn’t see in the original post. It’s important we compare and contrast existing methods of achieving a particular goal. If both approaches are to exist in parallel, they need to be clearly distinguished and have a solid reason for existing.
This was key for me, and something I didn’t see in the original post. It’s important we compare and contrast existing methods of achieving a particular goal. If both approaches are to exist in parallel, they need to be clearly distinguished and have a solid reason for existing. )
)