No problem, glad to help.
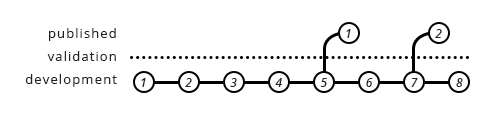
To map our terminology towards each other, it sounds like development from the illustrations above is your /version directory, and published is your /hero. Does that sound about right?
In your case, where Pyblish comes in is right at the point where a file is moved from /version to /hero. An implementation of that might look something like this.
import shutil
import pyblish.api as pyblish
class ConformShot(pyblish.Conformer):
def process_instance(self, instance):
# Get current filename
source = instance.data("path") # /version/ep08_seq01_shot0010_block_v002.ma
base = os.path.basename(source) # ep08_seq01_shot0010_block_v002.ma
name, ext = os.path.splitext(base)
# Compute new filename
name = name.rsplit("_", 2)[0] # ep08_seq01_shot001
base = name + ext # ep08_seq01_shot001.ma
# Produce output destination
dest = os.path.join(source, "..", "..", "hero", base)
dest = os.path.realpath(dest)
# Copy it
shutil.copy(source, dest)
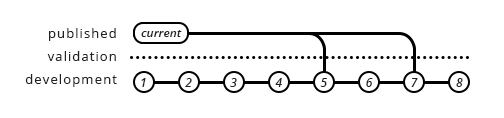
Which is, as you say, a push method as it overwrites the same output each time.
For a pull version, you could add a version number each time the file is about to be written. Building on the example above.
# Compute new filename
name = name.rsplit("_", 2)[0] + "v001" # ep08_seq01_shot001_v001
base = name + ext # ep08_seq01_shot001.ma
In which case you increment the v001 each time.
In a pull system, you could simply assert that the latest version available is always ready to be referenced. That way, there wouldn’t be a need for any external influences. Or how come you feel the need for a database?
You can validate either way. Whenever a file is about to be shared, you validate it. Whether it ends up overwriting or incrementing a version happens after it has been deemed valid. The line inbetween development and published in the illustrations above is meant to represent the step at which validation takes place. If validation fails, the file never reaches the other side.
A version control system (VSC) is useful in “push” systems. With pulling, the version control is in your naming convention - such as v001 - and you wouldn’t normally need both.
When pushing, a VCS can act as your versioning in that a user “pushes” a new hero file, overwriting anything that already exists as usual, but in this case, the previous version of the file is stored internally within the VCS and can be reverted back to if needed.
As a side-note, VCS’s like Subversion and Perforce differ from Git in that they both push towards a central repository that everyone references against. With a decentralised VCS like Git, you could potentially benefit from overwriting a hero file where the artist is pulling the latest version on his own behalf, effectively having as much control over versions as in a pulling system. At the cost of having to store an entire project on your local hard drive.
Pushing with VCS is very common in the game development industry, but less so in the commercial and film markets. There are giants who use this approach, ILM and Pixar come to mind. They use it because there are practical benefits such as improved disk space use - as a VCS can do smart things like deduplication - which is important when a production produces massive amounts of data each day. But they still have to work around the fact, as @mkolar put it, that the next time you open your file you might not be getting what you left it as because files may have been updated without you knowing about it.
Pinging @davidmartinezanim as he has more experience with it than I.
At the end of the day, it’s a balancing act and you choose the method that fits your production the best. Some love pulling, whereas others love pushing.